
들어가며
LangChain을 찍먹하려다가 ChatGPT를 쓰려면 토큰을 결제해야 한다는 사실을 깨달았습니다. 그런데 결제를 안 하고도 다른 LLM을 로컬에서 사용할 수 있다는 사실을 알게 되었습니다. 그게 바로 Ollama 입니다.
Ollama는 사용자가 대규모 언어 모델을 로컬에서 쉽게 설정하고 실행할 수 있게 해주는 고급 AI 도구입니다
Ollama를 사용하면 사용자는 Llama 2와 같은 강력한 언어 모델을 활용하고 자신만의 모델을 사용자 정의하고 생성할 수도 있다고 합니다.
그래서 LangChain을 찍먹하기 전에 Ollama 부터 찍먹해보도록 하겠습니다.
Ollama 설치
초기에는 MacOS에서만 제공한 것 같지만 현재는 Linux, Window에서도 사용 가능합니다 ^^
설치가 완료되면 귀여운 녀석이 추가됩니다.
Ollama에서 제공하는 모델들
Ollama는 llama2, mistral, codellama, Dolphin Phi, Neural Chat 등의 AI 모델을 제공합니다.
24.03.23 일 기준 인기 순으로 상위 4개의 라이브러리를 다음과 같습니다. llama2, mistral, codellama, gemma
이용 가능한 라이브러리는 다음을 주소를 확인해주세요

https://ollama.com/library?sort=popular
| Model | Reference | Feature | Parameters | Required memory | Size | Download |
|---|---|---|---|---|---|---|
| Llama 2 | Meta | 메타 AI가 개발한 원래 Llama 모델의 후속작으로, 더 큰 용량과 향상된 성능을 자랑합니다. | 7B | 8GB | 3.8GB | ollama run llama2 |
| Llama 2 13B | Meta | 용량이 각각 13B 파라미터로 원래 Llama 2보다 큰 대형 모델입니다. | 13B | 16GB | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | Meta | 용량이 각각 70B 파라미터로 원래 Llama 2보다 큰 대형 모델입니다. | 70B | 64GB | 39GB | ollama run llama2:70b |
| Mistral | Mistral AI | 2023년 9월 27일에 공개된 Mistral AI(프랑스)의 첫 오픈 소스 인공지능 모델입니다. | 7B | 8GB | 4.1GB | ollama run mistral |
| dolphin-phi | HuggingFace | 2.7B 무수정 돌고래 모델, Eric Hartford 제작, Microsoft Research의 Phi 언어 모델 기반. | 2.7B | under 8GB | 1.6GB | ollama run dolphin-phi |
| neural-chat | Mistral, Intel | NeuralChat은 고성능 챗봇 애플리케이션에 사용하도록 설계된 Mistral을 기반으로 Intel에서 출시한 미세 조정 모델입니다. | 7B | 8GB | 4.1GB | ollama run neural-chat |
| Starling | HuggingFace | Starling은 챗봇 유용성 향상에 초점을 맞춘 AI 피드백의 강화 학습을 통해 훈련된 대규모 언어 모델입니다.. | 7B | 8GB | 4.1GB | ollama run starling-lm |
| codellama | Meta | 메타 AI의 코딩 전문 LLM으로 다양한 프로그래밍 언어를 지원합니다. | 7B | 8GB | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | Meta | 메타 AI 모델로, 원본과 달리 비속어나 부적절한 내용 제한이 없습니다. | 7B | 8GB | 3.8GB | ollama run llama2-uncensored |
| Orca-Mini | HuggingFace (Pankaj Mathur) | GPT-4의 복잡한 설명 추적을 통한 점진적 학습 논문에 정의된 접근 방식을 사용하여 생성된 Orca 스타일 데이터 세트에 대해 훈련된 Llama 및 Llama 2 모델입니다. | 3B | under 8GB | 1.9GB | ollama run orca-mini |
| Vicuna | HuggingFace | Vicuna는 chat assistant 모델입니다. | 7B | 8GB | 3.8GB | ollama run vicuna |
| LLaVA | HuggingFace | LLaVA는 범용 시각 및 언어 이해를 위해 비전 인코더와 Vicuna를 결합한 다중 모드 모델로, 다중 모드 GPT-4의 정신을 모방한 인상적인 채팅 기능을 구현합니다. | 7B | 8GB | 4.5GB | ollama run llava |
| Gemma | Gemma는 Google DeepMind에서 구축한 경량의 최첨단 개방형 모델 제품군입니다. | 2B | under 8GB | 1.4GB | ollama run gemma:2b | |
| Gemma | 용량이 각각 7B 파라미터로 원래 GEmma보다 큰 대형 모델입니다. | 7B | 8GB | 4.8GB | ollama run gemma:7b |
Ollama 모델 설치 및 사용
터미널에서 ollama run <모델명> 만 입력하면 LLM 모델을 로컬에 설치할 수 있습니다.
# Meta에서 출시한 가벼운 AI 모델
ollama run llama2:7b
# Mistral AI에서 배포한 인기 있는 모델
ollama run mistral
# 코드 생성을 도와주는 AI모델
ollama run codellama:7b
# Google DeepMind에서 구축한 경량 AI 모델
ollama run gemma:7b
# 멀티 모달 AI모델
ollama run llava
설치가 완료되면 아래와 같은 프롬프트가 뜹니다
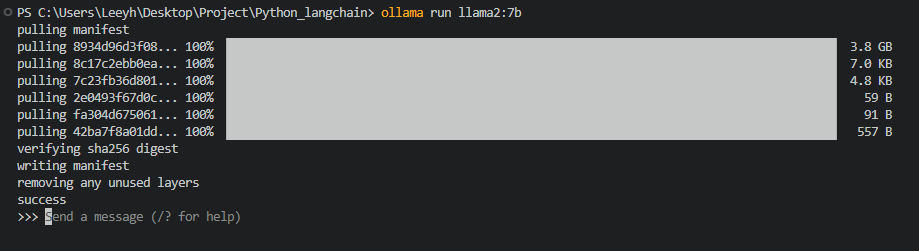
이제 여기서 chatGPT와 마찬가지로 생성형 AI를 이용할 수 있게 됩니다.
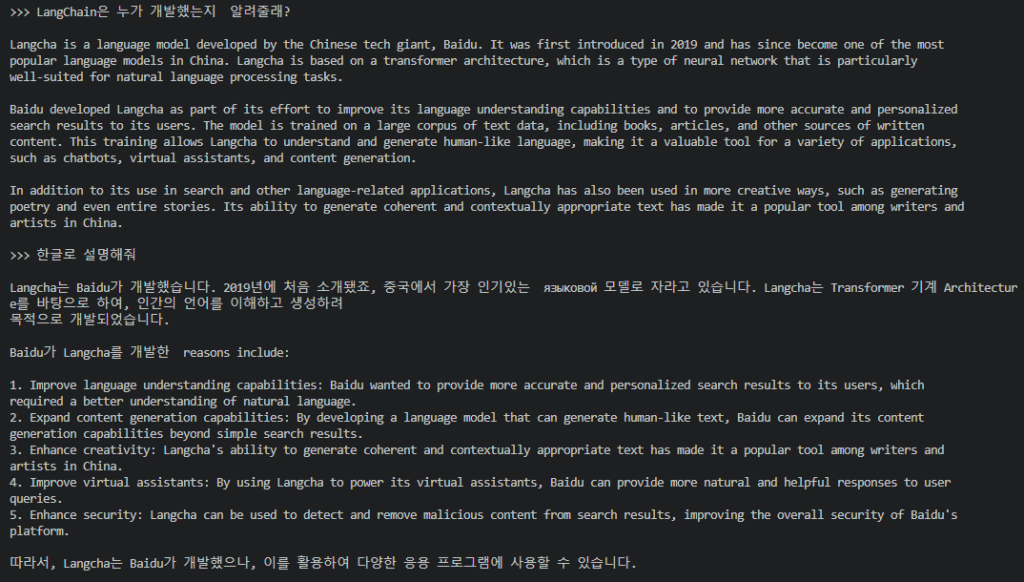
종료를 위해서는 Ctrl + D를 입력합니다.

마치며
LangChain을 브라우저에 띄워서 사용할 수도 있고 VS Code와 통합해서 사용할 수도 있다고 합니다.
이러한 기능들도 다음에 사용해봐야겠습니다.
