들어가며
여러 알고리즘을 공부하게 되면서 “재귀 함수”는 프로그래밍의 기초를 배우기 위해 초반에만 스쳐지나가는 녀석이 아니라는 것을 깨닫게 되었습니다. 재귀 함수는 되려 여러 알고리즘의 근간이 되는 녀석이라는 것도요.
이번 포스트에서는 재귀 함수의 설명들을 모아서 정리해보았습니다.
또한 특정 문제를 재귀함수와 반복문 솔루션으로 구현해 보고 결과를 비교도 해보았습니다.
재귀 함수 개념
“재귀 함수“는 문제를 해결하기 위해 문제를 더 작은 형태로 나누어 직접 또는 간접적으로 정의 내에서 자신을 호출하는 함수입니다.
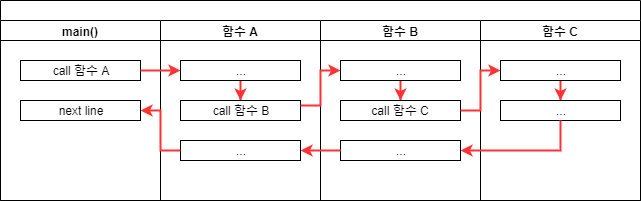
아래 그림이 재귀 함수 과정을 잘 설명 한 것 같아서 가져와 봤습니다.
재귀 함수는 아래와 같이 순서대로 실행이 되는데요.
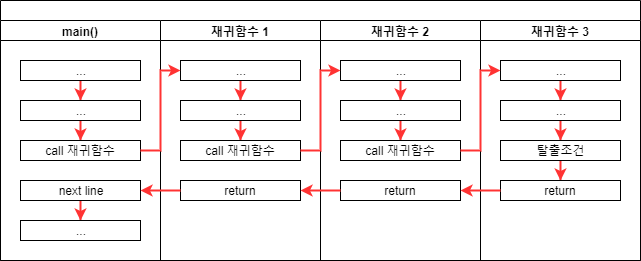
여기 예시에서는 main()함수 -> 재귀함수1 -> 재귀함수2 -> 재귀함수3 순으로 함수가 실행되는 것을 볼 수 있습니다.
모든 함수는 호출되면 메모리에 새로운 공간을 확보해서 매번 전혀 다른 공간에서 작업이 진행된다고 합니다.
main() 함수에서 처음 재귀함수를 실행했을 때 “재귀함수 1″이라는 메모리 공간이 생겨서 작업을 진행하다가 다시 재귀함수를 실행한다면 새로 “재귀함수 2″이라는 메모리 공간이 생성되는 방식입니다.
이렇게 재귀함수 3까지 메모리 공간을 생성하며 진행되다가 재귀함수 3이 종료 조건을 가지고 있다면 값을 return하면서
다시 재귀함수 3 -> 재귀함수 2 -> 재귀함수 1 -> main 함수 차례로 마무리가 됩니다.
위에서 언급한 “함수가 호출될 때 생기는 공간“은 “Call Stack“으로 이라고 불려 지는데요
아래와 같이 함수가 호출(call) 되면 스택 프레임이 push(메모리 할당)되고 함수가 종료되면 스택 프레임이 pop(메모리 할당 해제) 됩니다.
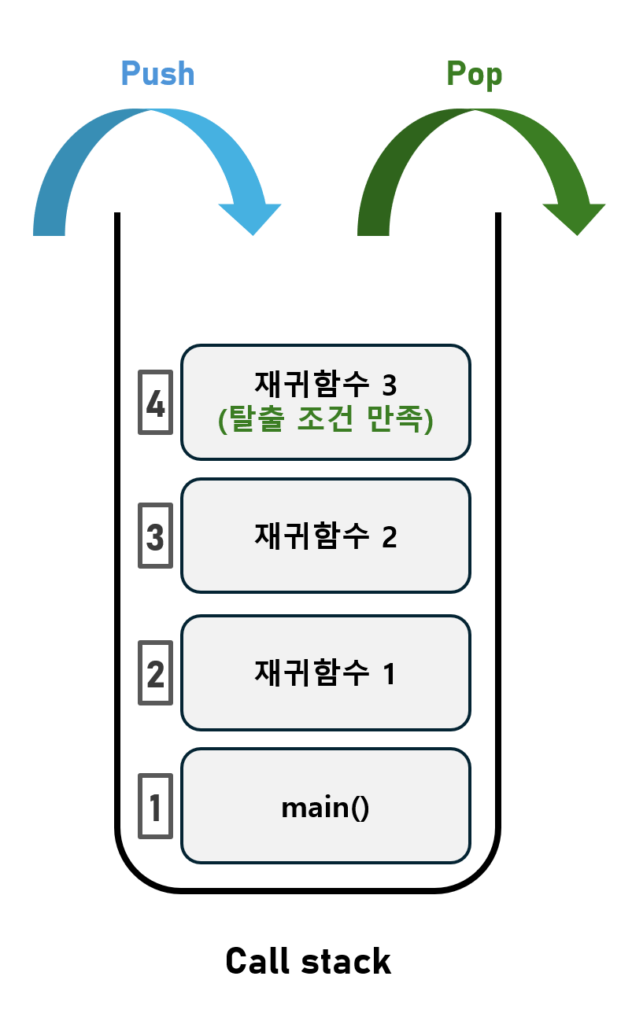
옆에 적힌 숫자 1->4 순으로 push 되고, 4->1 순으로 pop 되는 스택 구조임을 주목해야 합니다.
재귀 함수를 적용할 수 있는 알고리즘
Dynamic Programming
재귀 처럼 문제를 더 작은 하위 문제로 분해하여 해결합니다.
일반적으로 중복 계산을 피하기 위해 하위 문제의 결과를 저장하는 작업이 포함되므로 단순한 재귀 접근 방식에 비해 더 효율적인 솔루션을 얻을 수 있습니다.
이분 탐색
각 재귀 호출로 검색 간격을 절반으로 나누어 이진 검색 알고리즘에서 재귀 함수를 활용하여 대상 요소를 찾거나 간격이 비어 있을 때까지 검색 공간을 효과적으로 줄일 수 있습니다.
DFS
노드의 인접한 각 노드를 재귀적으로 방문하여 리프 노드에 도달하거나 이전에 방문한 노드를 만날 때까지 그래프를 더 깊이 탐색하여 깊이 우선 방식으로 효과적으로 그래프를 탐색합니다.
재귀 함수는 언제, 왜 사용하는 걸까?
재귀 함수는 문제를 더 작고 유사한 하위 문제로 나눌 수 있을 때 사용됩니다.
이는 트리나 그래프와 같은 중첩 구조와 관련된 작업에 특히 유용합니다.
그러나 무한 루프를 방지하기 위해 재귀 호출이 꼭 기저 사례 (base case)로 수렴되도록 주의해야 합니다.
기저 사례 (base case)란?
기저 사례란 쉽게 말해 “문제의 가장 작은 단위“이자 “재귀의 탈출 조건“입니다.
재귀 함수는 함수 정의 내에서 자신을 호출하기 때문에 탈출 조건이 없다면 무한이 자기 자신 내부를 계속 돌 수 밖에 없습니다.
때문에 기저 사례는 탈출 조건으로 사용되어 무한 재귀를 방지해줍니다.
재귀 함수 구현하기
예를 들어서 다음과 같은 형태의 이중 리스트가 있다고 가정해 보겠습니다.
li = [1,2,[1,2,3,4],5,8,10,[1,2,3,8,9],.....]이러한 중첩 리스트의 모든 요소를 합산하는 솔루션은 아래와 같이 반복문으로 풀 수 있습니다
반복문 사용
데이터의 구조가 복잡해지면 보통 몇 반복을 해야 하는지 예측 못할 때가 있습니다.
이런 경우 while 문을 사용합니다.
while 문에서 기저 사례로 수렴하도록 stack을 while 조건문으로 두고, while 문을 돌면서 pop()으로 stack 줄이는 과정을 주목합니다
def iterative_sum(nested_list):
total = 0
stack = [nested_list]
while stack:
current = stack.pop()
for element in current:
if isinstance(element, list):
stack.append(element)
else:
total += element
return total재귀 함수 사용
재귀 함수도 while문과 유사하게 기저 사례를 잘 설정해줘야 합니다.
해당 문제에서는 리스트 내에서 연산을 할 수 있는 가장 작은 단위가 정수의 연산이기 때문에 이 경우를 기저 사례로 잡고(7줄) 재귀가 추가 진행되지 않는 것을 확인 할 수 있습니다.
def recursive_sum(nested_list):
total = 0
for element in nested_list:
if isinstance(element, list):
total += recursive_sum(element)
else:
total += element
return total두 솔루션 모두 동일한 결과를 달성하지만 재귀적 접근 방식은 더 명확하고 간결한 코드를 제공해 주는 것을 확인 할 수 있습니다.
재귀 함수 대표 예제
팩토리얼
반복문으로 구현
def iter_factorial(num):
total = 1
while num:
if num != 1:
total = total * num
num -= 1
return total재귀 함수로 구현
def recursive_factorial(num):
if num == 1:
return 1
return num * recursive_factorial(num-1)반복문에 비교했을 때 재귀의 장점
iteration 솔루션에 비해 재귀가 빛을 발할 때는 트리나 그래프와 같은 계층적 데이터 구조를 탐색하고 검색하는 경우입니다.
향후 정리할 DFS나 DP와 같은 알고리즘에서 재귀가 많이 쓰인다는 거죠 ㅎㅎ
또한 문제가 자연스럽게 분할 정복 접근 방식으로 전환되는 특정 시나리오에서는 재귀의 시간 복잡성이 줄어들 수 있으므로 반복문 방식에 비해 더 효율적인 솔루션이 가능하다고 합니다.
재귀의 단점
하지만 재귀 함수는 분명한 단점이 있습니다.
재귀 깊이가 너무 커지면 스택 오버플로 오류가 발생하여 성능 문제가 발생할 수 있다는 점 입니다.
아래는 피보나치를 반복문으로 구현했을 때와 재귀 함수로 호출해 본 결과 입니다.
재귀로 구현한 코드는 40번째 피보나치 수를 구하는데 13.6초를 반복문으로 구하는 건 약 0초 만 소요된 것을 확인 할 수 있습니다.
재귀 함수가 마냥 좋지는 않다는 걸 단적으로 보여주는 예인거죠….!
피보나치
재귀 함수로 구현
def recursive_fibonacci(num):
if num == 1:
return 1
elif num == 0:
return 0
return recursive_fibonacci(num-1) + recursive_fibonacci(num-2)
start = time.time()
fibo_num = 40
answer = recursive_fibonacci(fibo_num)
print(f'{fibo_num}번째 피보나치 수는 {answer} 입니다.') # 40번째 피보나치 수는 102334155 입니다
print(f'소요시간 : {(time.time() - start):.2f}') # 소요시간 : 13.63반복문으로 구현
def iter_fibonacci(num):
fibo1, fibo2 = 1, 1
if num < 3:
fibo = 1
return fibo
while num >= 3:
fibo = fibo1 + fibo2
fibo1 = fibo2
fibo2 = fibo
num -= 1
return fibo
start = time.time()
fibo_num = 40
answer = iter_fibonacci(fibo_num)
print(f'{fibo_num}번째 피보나치 수는 {answer} 입니다.') # 40번째 피보나치 수는 102334155 입니다
print(f'소요시간 : {(time.time() - start):.2f}') # 소요시간 : 0.00마치며
재귀 함수 구현의 초보 단계 일 때 느꼈던 어려움은 2가지 있었습니다.
첫째. 이중 재귀
피보나치 함수 처럼 이중 재귀의 경우 정말 간단한 아이디어 인데도 바로 구현이 안 되더군요…ㅎ
“문제를 <언제>, <어떻게> 작은 단위로 쪼개야 문제 푸는데 용이할까?” 가 중요한 포인트인 거 같은데 이는 문제를 여럿 풀어봐야 감이 더 명확하게 잡힐 것 같습니다.
둘째. 탈출 조건
첫번째 사항과도 이어지는건데, 문제를 어떻게 쪼개야 하는지 명확한 계획이 세워졌다면 아마 동시에 탈출 조건도 자연스레 결정이 되는 것 같습니다.
이를 명확하게 정하고 구현을 시작해야지, 막연하게 생각하고 바로 구현을 하면 중간에 헛고생을 하는 것 같았습니다.
재귀 함수를 공부하면서 정리해보니 처음 공부하시는 분들이라면 시간이 걸리시더라도 꼭 직접 손으로 구현해 보면 좋을 것 같다는 생각이 들었습니다.
작은 단위로 분할해서 풀어야 하는 문제들을 빨리 만나보고 싶어지네요 ㅎ
참고하면 좋은 글