
Hadoop MapReduce 는 분산 데이터 처리를 위한 프로그래밍 모델이자 처리 기술입니다.
key, value 형태의 자료구조를 기반으로 데이터를 처리하는 메커니즘를 가지는데요. MapReduce의 대략적인 모습은 아래와 같습니다.
데이터를 Split하여 분산 저장 -> 데이터를 Map 단계에서 key:value pair로 변환 -> Reduce 단계에서 key:value 데이터를 집계하여 최종 데이터를 결정하는 단계를 거칩니다.
해당 포스트는 KMOOC 빅데이터 프레임워크 강의 내용을 기반으로 정리한 글 입니다.
Hadoop MapReduce 동작 순서
MapReduce는 작업을 더 작은 하위 작업(Map 작업)으로 나누고 병렬로 처리한 다음 결과를 결합합니다(Reduce).
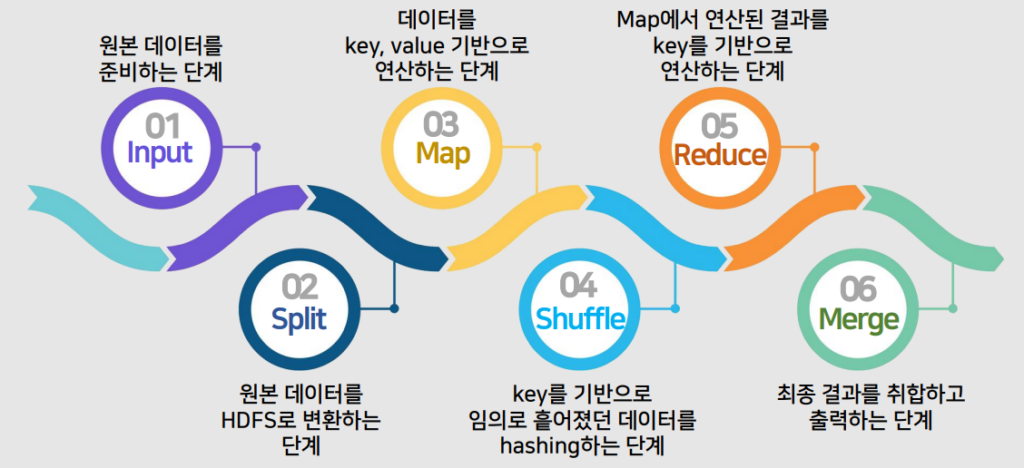
1. Input
입력은 처리하려는 데이터를 나타냅니다. 예를 들어 문장이 포함된 텍스트 파일이 여러 개 있다고 가정해 보겠습니다.
File1: "apple banana apple"
File2: "banana apple orange"
File3: "banana orange orange"2. Split
Split은 입력 데이터를 병렬로 처리할 수 있는 더 작은 chunk로 나눕니다. 각 chunk는 별도의 Mapper에 의해 처리됩니다.
예를 들어 Split 단계에서는 텍스트 파일을 줄이나 단어별로 나눌 수 있습니다.
3. Map
Map은 각 데이터 chunk에 적용되는 기능입니다. 데이터를 처리하고 중간 key-value 쌍을 생성합니다.
단어 개수 예의 경우 mapper 함수는 각 단어를 읽고 키가 단어이고 값이 1인 키-값 쌍을 내보냅니다.
Mapper Output:
("apple", 1)
("banana", 1)
("apple", 1)
("banana", 1)
("apple", 1)
("orange", 1)
("banana", 1)
("orange", 1)
("orange", 1)4. Shuffle
셔플은 동일한 키에 해당하는 모든 값이 함께 그룹화되도록 중간 key-value 쌍을 재배포하는 프로세스입니다.
이 단계는 프레임워크에 의해 처리되는 경우가 많으며 네트워크를 통해 데이터를 정렬하고 전송하는 작업이 포함됩니다.
예를 들어 셔플 단계는 각 단어의 모든 개수를 그룹화합니다.
Shuffled Output:
("apple", [1, 1, 1])
("banana", [1, 1, 1])
("orange", [1, 1, 1])5. Reduce
Reduce는 섞인 데이터에 적용되는 기능입니다. 그룹화된 key-value 쌍을 처리하고 최종 출력을 생성합니다.
단어 개수 예에서 Reducer 함수는 각 키의 값 목록을 합산합니다.
Reducer Output:
("apple", 3)
("banana", 3)
("orange", 3)6. Merge
Merge은 Reduce 단계의 결과를 최종 출력에 결합합니다.
이는 처리된 결과가 집계되어 출력에 기록되는 마지막 단계입니다.
단어 개수 예의 경우 병합 단계는 단순히 각 단어의 최종 개수를 출력합니다.
Final Output:
"apple: 3"
"banana: 3"
"orange: 3"Note. Map, Shuffle, Reduce 단계에서의 데이터 이동 과정
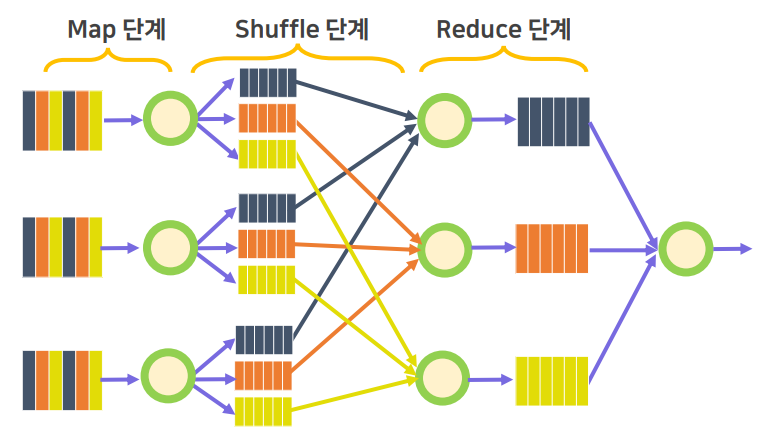
- Map 단계에서 용량 단위로 분할된 데이터를 임의의 노드에서 연산을 수행
- Shuffle을 통해 key 값을 기준으로 같은 key의 값은 같은 Reducer로 데이터가 이동
- Reducer에서는 동일한 key 끼리 모여 있음
워커 노드 상에서의 MapReduce 동작 방법
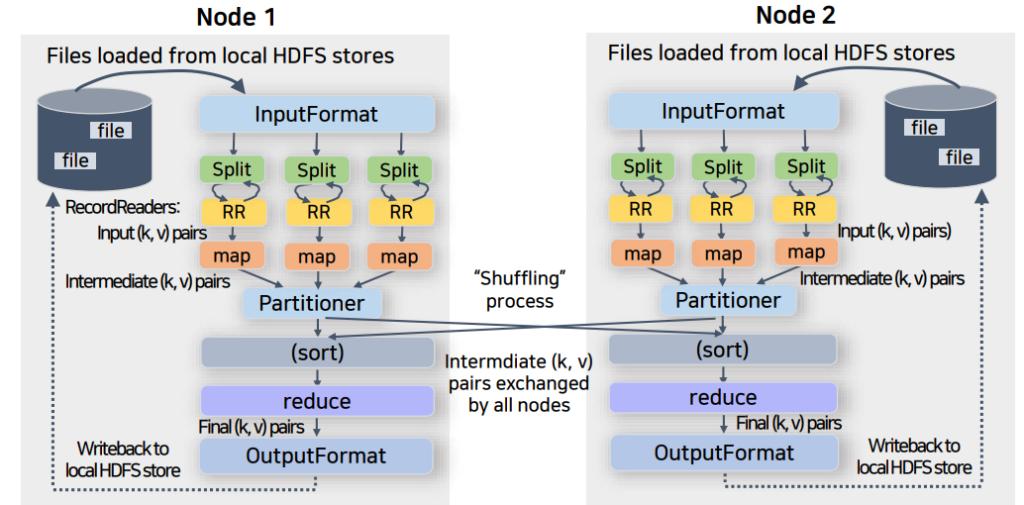
- 각 노드의 Split 만큼 Map의 개수가 결정됨
- Reduce는 사용자가 설정한 개수만큼 설정함
- 데이터의 성격을 기반으로 하여 결정
- 보통 키의 개수로 Reducer를 설정할 수 있는데, 너무 적거나 너무 많은 reducer를 두면 시스템 성능에 영향을 미침
- 각 노드에 여러 Map과 Reduce가 존재할 수 있음
- Map과 Reduce는 유휴 Container를 만나 구동됨
노드마다 데이터를 split 한 이후에 Map 과정에 의해 key-value가 생성됩니다. 각 노드에서 shuffling 과정을 거친 후, 노드마다 존재하는 1개의 reducer(사용자 지정)로 key-value가 이동하는 것을 볼 수 있습니다.
MapReduce 예시
Word count를 예시로 한 MapReduce
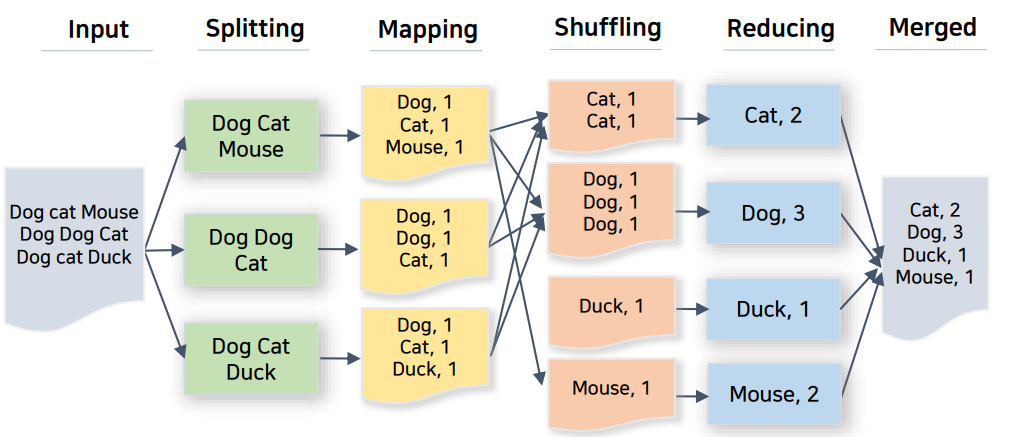
여러 단어가 적힌 굉장히 큰 input 파일이 가정해봅니다. 여기서 각 단어의 수를 세고 싶다고 가정해봅니다.
우선 input 파일을 HDFS를 통해 3개로 Split 합니다.
Mapper에서 key-value 쌍으로 만듭니다.
shuffling을 통해 key를 기반으로 그룹화하여 각 노드에 위치시킵니다.
Reducer를 통해 각 key에 대한 연산을 마무리 합니다
Merged 과정을 통해 Reducer의 결과를 통합하여 마무리합니다.
Hadoop MapReduce 실습
실습 파일을 다운로드 합니다.
git clone https://github.com/CUKykkim/hadoop-docker코드를 다운 받으면 hadoop-docker 라는 폴더가 생성됩니다. 해당 디렉토리로 이동합니다.
hadoop-docker 폴더 안에서 다음 명령어를 수행합니다.
docker compose up컨테이너 생성이 완료되었는지 확인합니다.
docker ps
hadoop NameNode 컨테이너로 진입합니다.
docker exec -it namenode /bin/bash먼저 HDFS의 디렉토리를 만들어주겠습니다.
hdfs dfs -mkdir -p /user/hduser hdfs dfs -ls /user컨테이너에서 로컬 파일 시스템 상에서 입력 데이터가 있는 곳으로 이동합니다.
cd /hadoop-data/HadoopWithPython/python/MapReduce/HadoopStreaming위에서 생성한 HDFS 디렉토리에 input.txt를 올립니다.
hdfs dfs -put input.txt /user/hdusermapper와 reducer를 다음과 같이 작성합니다.
mapper.py
for line in sys.stdin: # stdin 으로 Split 입력
line = line.strip() # 띄어쓰기, 탭, 엔터를 포함한 whitespace 제거
words = line.split() # line을 단어로 쪼개기
for word in words: # key value 쌍으로 표현
print ('%s\t%s' % (word, 1)mapper 코드 검증
$ cat hadoop.txt
The Cyber University of Korea
The Cyber
The$ cat hadoop.txt | python3 mapper.py | sort –k 1
The 1
Cyber 1
The 1
Cyber 1
The 1
University 1
of 1
Korea 1reducer.py
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip() # 띄어쓰기, 탭, 엔터를 포함한 whitespace 제거
word, count = line.split('\t') # mapper로부터 온 데이터를 탭을 구분으로 파싱
try:
count = int(count) # count를 정수형으로 변환
except ValueError:
continue
if current_word == word: # 현재 단어가 이전의 단어와 같다면, 1을 카운팅
current_count += count
else:
if current_word: # 현재 단어가 이전의 단어와 다르면, key, value 값 출력
print ('%s\t%s' % (current_word, current_count))
current_count = count
current_word = word
if current_word == word: # 마지막 단어 출력
print ('%s\t%s' % (current_word, current_count))reducer.py 코드 검증
$ cat hadoop.txt | python3 mapper.py | sort –k1 1 | python3 reducer.py | sort –k 2 -r
Cyber 2
The 2
University 1
of 1
Korea 1Hadoop Cluster를 통하여 MapReduce를 수행해 줍니다.
hadoop jar /opt/hadoop-3.2.1/share/hadoop/tools/lib/hadoop-streaming-3.2.1.jar \n
-input /user/hduser -output /user/wordcount \n
-mapper mapper.py -file mapper.py -reducer reducer.py -file reducer.pyhadoop jar- JAR 파일에 지정된 Hadoop 작업을 실행합니다. 이 경우 Hadoop Streaming JAR을 실행하고 있습니다.
/opt/hadoop-3.2.1/share/hadoop/tools/lib/hadoop-streaming-3.2.1.jar- Hadoop Streaming JAR 파일 경로입니다.
- Hadoop 스트리밍 유틸리티는 Hadoop 도구 라이브러리에 있는 JAR 파일로 제공됩니다.
-input /user/hduser- HDFS의 입력 디렉터리 또는 파일을 지정합니다.
-output /user/wordcount- MapReduce 작업의 결과가 저장될 HDFS의 출력 디렉터리를 지정합니다
-mapper mapper.py- 매퍼로 사용할 실행 파일이나 스크립트를 지정합니다.
- 이 경우 mapper.py는 Map 단계에서 입력 데이터를 처리하는 데 사용되는 Python 모듈입니다.
-file mapper.py- 이 옵션을 사용하면 mapper.py가 Hadoop 클러스터 노드에 제공됩니다.
- Mapper 작업을 실행할 모든 노드에 이 파일을 배포하도록 Hadoop에 지시합니다.
-reducer reducer.py- Reducer로 사용할 실행 파일이나 스크립트를 지정합니다
-file reducer.py- reducer.py 스크립트가 Hadoop 클러스터 노드에 제공됩니다.
- 이 파일을 reducer 작업을 실행할 모든 노드에 배포하도록 Hadoop에 지시합니다.
HDFS 상에서 MapReduce 결과를 확인 할 수 있습니다.
hdfs dfs -cat /user/wordcount/part-00000