실시간 데이터 처리란?
실시간 데이터 처리에는 일반적으로 대기 시간을 최소화하면서 데이터가 생성될 때 지속적으로 데이터를 수집, 분석 및 처리하는 작업을 의미합니다.
이를 통해 사기 탐지, 실시간 분석, 모니터링 시스템과 같은 애플리케이션에 중요한 즉각적인 통찰력과 대응이 가능해집니다.
실시간 데이터
| Category | Examples |
|---|---|
| 센서 데이터 | 온도 판독값, 습도 수준, 압력 측정, GPS 좌표 |
| 재무 데이터 | 주식 시장 가격, 환율, 암호화폐 가치, 거래 데이터 |
| SNS 데이터 | 트윗, Facebook 게시물, Instagram 좋아요, 실시간 비디오 스트림 |
| 웹/앱 데이터 | 클릭스트림, 서버 로그, 오류 로그, 사용자 활동 로그 |
| 통신 데이터 | 통화 내역 기록, 네트워크 트래픽 데이터, SMS 로그, VoIP 통화 기록 |
| 의료/건강 데이터 | 환자 생체신호, 의료기기 데이터, 웨어러블 건강기기 데이터 |
| 소매 데이터 | POS 거래, 재고 수준, 고객 검색 행동, 온라인 구매 |
| 교통 데이터 | 차량 추적, 교통 정보, 배송 추적, 대중 교통 업데이트 |
| 환경 데이터 | 기상 조건, 대기 질 지수, 수질 측정 |
| 게임 데이터 | 플레이어 액션, 게임 내 이벤트, 순위표 업데이트, 라이브 스트리밍 |
실시간 데이터 처리 방식 요약
| 기법 | 설명 | 예시 |
|---|---|---|
| Time-Agnostic | 시간 정보나 순서에 상관없이 데이터를 독립적으로 처리 | 특정 키워드 발생 횟수 세기 |
| Filtering | 조건에 맞는 데이터만 처리하고 나머지는 버림 | 특정 IP 주소의 네트워크 트래픽 필터링 |
| Inner Joins | 두 스트림 데이터를 공통된 키로 결합 | 사용자 ID로 사용자 행동과 제품 정보 결합 |
| Approximation Algorithms | 일부 데이터로 전체 데이터에 대한 근사치를 계산 | HyperLogLog로 고유 값 개수 추정 |
| Windowing | 데이터를 시간 간격(윈도우)으로 나누어 처리 | 1분 단위 웹사이트 방문자 수 집계 |
실시간 데이터 처리 방식 1 : 마이크로 배치 처리
마이크로 배치 처리에는 실시간 데이터를 작은 고정 크기 배치로 수집한 다음 이러한 배치를 정기적으로 처리하는 작업이 포함됩니다.
특징
스트림 처리보다 구현 및 관리가 더 쉽습니다.
배치 간격으로 인해 약간의 지연이 발생하지만 거의 실시간 애플리케이션에 적합합니다.
Apache Spark Streaming은 마이크로 배치를 사용하여 데이터를 처리합니다.
각 마이크로 배치가 처리되고 다음 배치가 처리되기 전에 결과가 출력됩니다.
동작 방식
Fixed windows
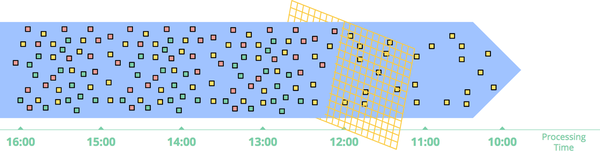
입력 데이터를 고정 크기 window로 설정한 다음 각 window를 별도의 제한된 데이터 소스(tumbling windows이라고도 함)로 처리하는 것입니다.
특히 이벤트가 디렉터리 및 파일 계층에 기록될 수 있는 로그와 같은 입력 소스의 경우 Fixed windows를 적용할 수 있습니다
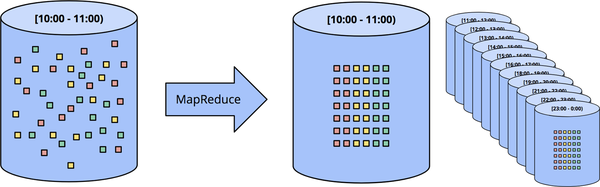
그림. 클래식 배치 엔진을 사용하는 임시 고정 window을 통한 스트림 데이터 처리
NOTE. Fixed windows의 어려움
지연 문제
기본적으로 시간 기반 셔플을 수행했기 때문에 이런 종류의 작업은 얼핏 매우 간단해 보입니다.
그러나 실제로 대부분의 시스템에는 여전히 처리해야 할 완전성 문제가 있습니다
- 네트워크 분할로 인해 일부 이벤트가 로그로 이동하는 도중 지연되면 어떻게 될까요?
- 이벤트가 전역적으로 수집되어 공통 위치로 전송되어야 한다면 어떻게 될까요?
- 처리하기 전에 이벤트가 모바일 장치에서 오는 경우 어떻게 해야 합니까?
이는 일종의 완화 기술이 필요할 수 있음을 의미합니다.
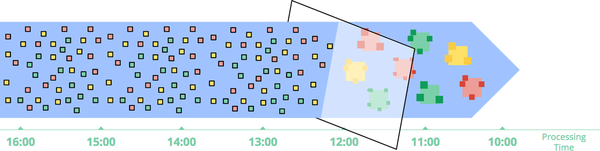
예를 들어 모든 이벤트가 수집되었다고 확신할 때까지 처리를 지연하거나 데이터가 도착할 때마다 지정된 window에 대한 전체 배치를 다시 처리하는 방식을 고려할 수 있습니다.
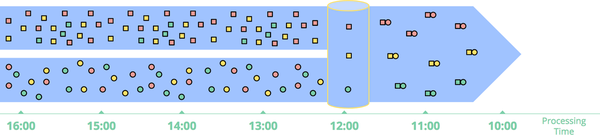
Sessions 문제
스트림 데이터를 세션과 같은 보다 정교한 window 전략으로 처리하려고 할 때 더욱 심각해집니다.
세션은 일반적으로 비활성 기간으로 인해 종료되는 활동 기간으로 정의됩니다. (그림의 빨간색 표시)
배치 크기를 늘려 session 수를 줄일 수 있지만 이렇게 되면 latency가 늘어나는 대가를 치르게 됩니다.
또 다른 옵션은 이전 실행의 세션을 연결하는 논리를 추가하는 것입니다.
하지만이 경우도, 그 비용이 더욱 복잡해지게 됩니다.
실시간 데이터 처리 방식 2: 스트림 처리
스트림 처리에는 지연을 최소화하면서 데이터가 도착하는 대로 지속적으로 처리하는 작업이 포함되며, 대개 실시간입니다.
고정된 배치 간격은 없습니다. 데이터는 지속적으로 처리됩니다.
결과는 실시간 또는 거의 실시간으로 생성됩니다.
특징
지속적인 데이터 흐름을 처리해야 하기 때문에 구현 및 관리가 더 복잡합니다.
Apache Flink 및 Apache Kafka Streams는 스트림 처리를 위한 프레임워크입니다.
동작 방식
Time agnostic
데이터가 들어오는 대로 즉각적으로 처리하여 실시간성을 확보하며 간단하게 구현할 수 있습니다.
데이터의 도착 순서나 타임스탬프가 중요하지 않은 경우에 적합합니다.
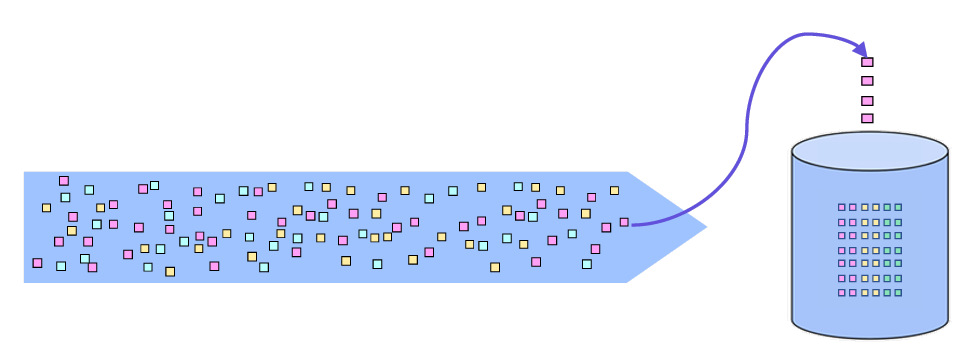
Time agnostic 예시
- 실시간으로 특정 키워드의 발생 횟수를 세는 경우.
- 각 센서의 값을 시간에 관계없이 단순히 합산하는 경우.
Filtering 방식
모든 데이터를 처리하지 않고, 처리하고자 하는 데이터를 필터링하여 처리합니다.
Time agnostic 방식의 기본적인 형태인데요. 초기에 불필요한 데이터를 걸러내어, 전체 데이터 처리량을 줄여 성능을 향상시킵니다.
Filtering 예시
- 네트워크 트래픽 중 특정 IP 주소에서 오는 패킷만 분석하는 경우.
- 온도가 30°C 이상인 센서 데이터만 처리하는 경우.
Inner Joins 방식
두 데이터 스트림 간의 공통된 키를 기준으로 데이터를 결합하는 방법입니다.
두 스트림의 데이터가 모두 존재해야 결합이 이루어집니다.
서로 다른 데이터 소스의 관련 정보를 통합할 때 유용합니다.
Inner Joins 예시
- 사용자 행동 데이터와 제품 정보 데이터를 사용자 ID를 기준으로 결합하여 분석하는 경우.
- 실시간 위치 정보와 날씨 정보를 지역 ID를 기준으로 결합하는 경우.
Approximation Algorithms
데이터의 일부만을 사용하여 전체 데이터에 대한 근사치를 계산하는 방법입니다.
정확도는 다소 떨어질 수 있지만, 대용량 데이터에서 빠르고 효율적으로 결과를 얻을 수 있습니다.
Approximation Algorithms 예시:
- Count-Min Sketch를 사용하여 데이터의 빈도를 근사치로 계산하는 경우.
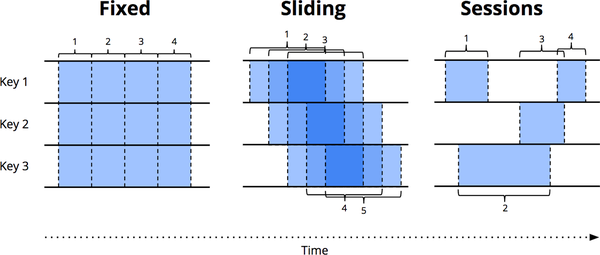
Windowing
데이터 스트림을 시간 간격(윈도우)으로 나누어 각 윈도우 내에서 데이터를 처리하는 방법입니다.
시간 기반 처리로, 데이터의 시간 정보와 순서를 고려합니다.
슬라이딩 윈도우, 텀블링 윈도우 등 다양한 윈도우 전략이 있습니다.
예시:
- 1분 단위로 웹사이트 방문자 수를 집계하는 경우.
- 지난 10분 동안의 센서 데이터 평균을 1분 간격으로 계산하는 경우
NOTE. Batch 방식과 Windowing 방식의 차이
windowing:
- 짧은 지연 시간, 거의 실시간 처리를 위해 설계
- 정의된 시간을 기준으로 들어오는 데이터를 지속적으로 처리
batch:
- 처리 전에 전체 배치가 수집 될 때까지 기다리기 때문에 일반적으로 더 긴 대기시간이 필요
- 수집 기간 이후에 데이터를 일괄 처리
실시간 데이터 처리에 필요한 기술적 요소
Buffer
버퍼는 실시간 데이터 처리에서 데이터를 한 장소에서 다른 장소로 전송하거나 데이터 처리 파이프라인의 다른 단계들 간에 전송하는 동안 데이터를 일시적으로 저장하는 공간입니다.
버퍼는 데이터 생성자(센서 또는 입력 장치)와 데이터 소비자(프로세서 또는 저장 시스템) 간의 속도 차이를 관리하는 데 도움을 줍니다.
이는 데이터 흐름이 원활하고 효율적으로 이루어지도록 하여, 어느 한 요소도 과부하되지 않게 합니다.
이 임시 저장소는 버퍼 설계 및 애플리케이션 요구 사항에 따라 메모리(RAM) 또는 디스크에 있을 수 있습니다.
이를 통해 데이터 생산이 소비보다 빠르더라도 데이터 손실이나 오버플로가 발생하지 않습니다.
참고한 글
1. Streaming 101 – Streaming Systems [Book] (oreilly.com)