
Apache Spark Action 은 RDD(Resilient Distributed Dataset)의 변환에 의해 정의된 전체 계산 계획의 실행을 트리거하는 작업입니다.
action은 Spark에 계산을 수행하고 결과를 생성하도록 지시하여 Spark가 클러스터 노드에서 실행될 작업을 시작하도록 합니다.
action의 예로는 RDD의 모든 데이터를 드라이버 프로그램으로 검색하는 ‘collect()’, RDD의 요소 수를 계산하는 ‘count()’ 등이 있습니다.
Spark Action 함수 정리
| Action Function | Purpose | Example | Input | Result |
|---|---|---|---|---|
collect() | 데이터세트의 모든 요소를 드라이버에 배열로 반환 | rdd.collect() | [1,2,3,4] | [1, 2, 3, 4] |
count() | 데이터세트의 요소 수를 반환 | rdd.count() | [1,2,3,4] | 4 |
first() | 데이터세트의 첫 번째 요소를 반환 | rdd.first() | [1,2,3,4] | 1 |
take(n) | 데이터세트의 첫 번째 n 요소를 반환 | rdd.take(2) | [1,2,3,4] | [1, 2] |
takeOrdered(n) | 데이터세트의 첫 번째 n 요소를 오름차순으로 반환 | rdd.takeOrdered(2) | [3, 1, 2, 4] | [1, 2] |
top(n) | 데이터세트에서 상위 n 요소를 반환 | rdd.top(2) | [1,2,3,4] | [4, 3] |
reduce(func) | 함수를 사용하여 데이터 세트의 요소를 집계 | rdd.reduce(lambda x, y: x + y) | [1,2,3,4] | 10 |
countByKey() | key-value RDD에서 각 키 값에 해당하는 값 카운트 | rdd.countByKey() | [(“a”, 1), (“b”, 2), (“a”, 3)] | {'a': 2, 'b': 1} |
foreach(func) | 데이터세트의 각 요소에 함수를 적용 | rdd.foreach(lambda x: print(x)) | [1,2,3,4] | (prints each element) |
takeSample() | 데이터 세트의 고정 크기 샘플링 하위 집합을 반환 | rdd.takeSample(False, 2) | [1,2,3,4] | [3, 1] (result can vary) |
saveAsTextFile() | 데이터 세트를 텍스트 파일 또는 텍스트 파일 세트로 저장 | rdd.saveAsTextFile("path/to/file") | [1,2,3,4] | (writes data to file) |
saveAsSequenceFile() | 데이터 세트를 Hadoop SequenceFile로 저장 | rdd.saveAsSequenceFile("path/to/file") | [1,2,3,4] | (writes data to file) |
saveAsObjectFile() | 데이터세트를 간단한 Java 개체 파일로 저장 | rdd.saveAsObjectFile("path/to/file") | [1,2,3,4] | (writes data to file) |
aggregate() | 각 파티션의 요소를 집계한 다음 파티션 전체의 결과를 집계합니다. | rdd.aggregate((0, 0), lambda acc, val: (acc[0] + val, acc[1] + 1), lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1])) | [1,2,3,4] | (10, 4) |
fold() | 함수와 0 값을 사용하여 데이터세트의 요소를 집계 | rdd.fold(0, lambda x, y: x + y) | [1,2,3,4] | 10 |
lookup(key) | ‘key’ 키에 대한 RDD의 값 목록을 반환 | rdd.lookup('a') | [(“a”, 1), (“b”, 2), (“a”, 3)] | [1, 3] |
참고하면 좋은 글
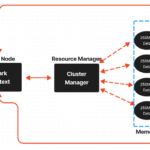
Spark 이해하기 1. Spark 특징 / 구조
Apache Spark는 빅 데이터 처리 및 분석을 위해 설계된 오픈 소스 분산 컴퓨팅 시스템입니다. Spark는 Disk 기반의 Hadoop 처리 방식을 개선하여 처리속도를 높인 프레임워크인데요.
Spark 이해하기 2. Spark RDD
Spark RDD 는 Resilient Distributed Dataset의 약자로써 “복원력 있는 분산 데이터세트”를 나타냅니다. Spark RDD 는 빅데이터 처리를 단순화하고 속도를 높이도록 설계된 Apache Spark의 핵심 데이터 모델입니다.

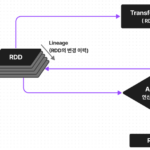
Spark 이해하기 3. Spark transformation
Spark Transformation 은 작업을 즉시 실행하지 않고 원본 RDD의 각 요소에 함수를 적용하여 새 RDD를 생성하는 RDD(Resilient Distributed Datasets)에 대한 작업입니다.
Spark 이해하기 3. Spark transformation – H-A (hangbok-archive.com)