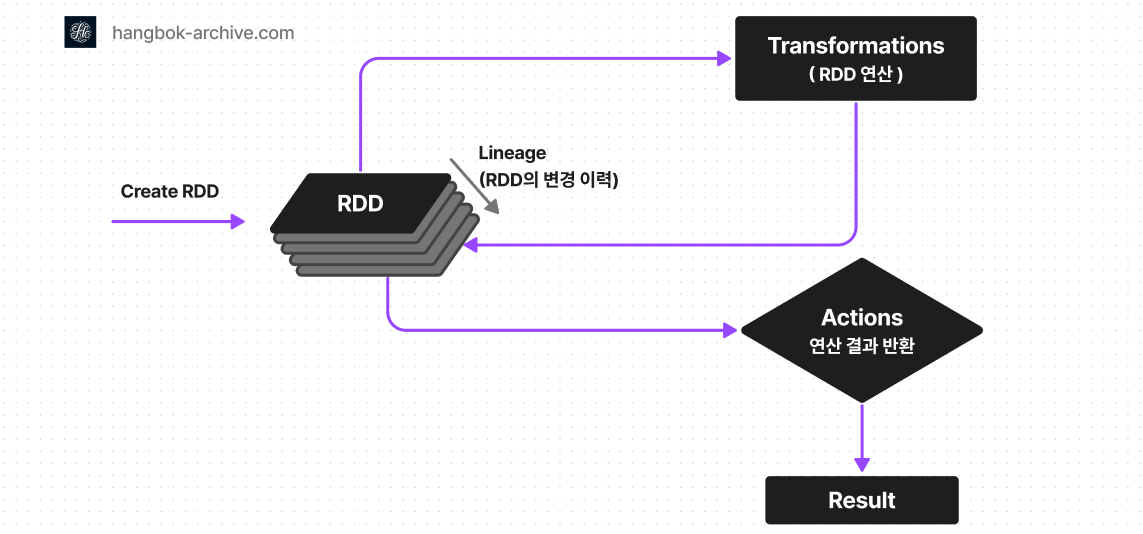
Spark RDD 는 Resilient Distributed Dataset의 약자로써 “복원력 있는 분산 데이터세트”를 나타냅니다.
이는 빅 데이터 처리를 단순화하고 속도를 높이도록 설계된 Apache Spark의 핵심 데이터 모델입니다.

Spark RDD 모델은 Transformation 단계에서 연산이 진행되며 해당 단계를 거칠 때 마다 변경되는 모든 변경 이력을 Lineage에 저장 합니다.
그리고 Transformation이 끝나면 Action 연산 후 결과를 데이터로 저장합니다.
Spark RDD 특징
In-memory Computation
RDD 에서 제공하는 operation은 연산의 중간 결과를 디스크에 저장하지 않고 메모리 상에 상주시킵니다.
NOTE. RDD operation
RDD operation은 Transformation과 Action 단계가 있습니다.
Transformation : RDD에서 다른 RDD로 만드는 변형 연산
Actions : RDD의 최종 연산으로 RDD에서 RDD가 아닌 data로 저장
Immutability 불변성
RDD를 생성한 후에는 해당 데이터를 변경할 수 없습니다. 대신 Transformation을 수행하여 항상 새로운 RDD를 생성합니다.
이는 복원력을 위해서 기존 데이터를 변경하기 보다는 새로운 버전으로 저장하는 방식으로 진행되는 것으로 이해하면 될 것 같습니다.
Lineage 계통
Transformation으로 발생하는 모든 RDD는 lineage에 기록되어 RDD 이력에 저장됩니다.
메모리 연산 특성 상 연산 과정 중 발생하는 fault로 인해 연산 결과가 유실되는 것을 방지하기 위함입니다.
lineage는 Spark driver에 저장합니다.
Lazy Execution 지연 수행
RDD에 대한 작업은 즉시 실행되지 않습니다. 대신 Spark는 action(예: 데이터 수집)이 호출되면 실제 연산을 수행합니다.
action operation까지 실제 연산을 수행하지 않는 이유는 RDD lineage를 확인하여 전체 연산을 미리 고려한 후 최적화된 작업 분산을 하기 위함 입니다.

참고하면 좋은 글
참고한 글
https://intellipaat.com/blog/tutorial/spark-tutorial/programming-with-rdds/
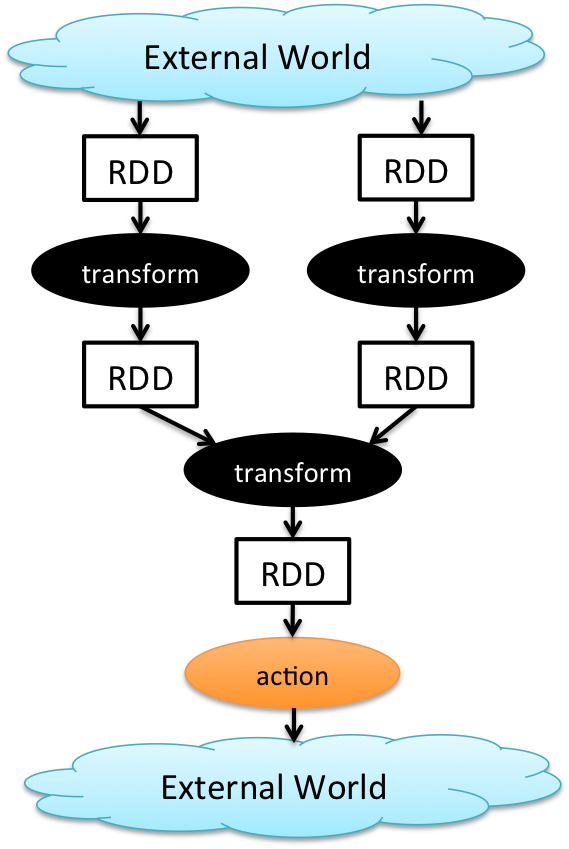
https://medium.com/@aristo_alex/how-apache-sparks-transformations-and-action-works-ceb0d03b00d0