Spark Transformation 은 작업을 즉시 실행하지 않고 원본 RDD의 각 요소에 함수를 적용하여 새 RDD를 생성하는 RDD(Resilient Distributed Datasets)에 대한 작업입니다.
이러한 Transformation은 lazy(게으른) 특성을 가지고 있습니다. 즉, 결과가 필요한 작업이 호출될 때만 계산이 수행됩니다. 이로써 계산의 최적화가 가능하게 만드는 거죠.
Spark transformation 특성
파티션 개념
Spark의 파티션은 병렬 처리 및 데이터 배포의 기본 단위입니다.
각 파티션은 Spark 클러스터의 별도 작업에 의해 독립적으로 처리 될 수 있습니다.
Spark는 데이터를 파티션으로 분할함으로써 클러스터의 여러 노드에서 동시에 많은 파티션을 처리할 수 있습니다.
파티션은 데이터 지역성을 최적화하는 데 도움이 됩니다. Spark는 네트워크를 통한 데이터 이동을 최소화하기 위해 데이터가 있는 곳에서 데이터를 처리하려고 합니다
하둡에서의 split 개념과 spark의 partition 개념이 유사하다고 보면 될 것 같습니다.
Narrow transformation
Spark의 narrow transformation은 상위 RDD의 각 파티션이 최대 하나의 하위 RDD 파티션에서 사용되는 작업을 의미합니다.
이는 데이터가 네트워크 전체에서 섞일 필요가 없음을 의미합니다.
예를 들면 map, filter, mapPartitions 등이 있습니다.
Wide transformation
wide transformation에는 상위 RDD의 여러 파티션에 있는 데이터가 네트워크 전체에서 결합되거나 섞여 하위 RDD를 형성하는 작업이 포함됩니다.
groupByKey, reduceByKey, join등이 wide transformation에 포함됩니다.
이러한 transformation에는 일반적으로 데이터 셔플이 필요하며, 이는 데이터가 네트워크로 이동 됨을 의미합니다.
따라서 시간이 더 많이 걸리고 리소스 집약적일 수 있으며 복구 비용이 높습니다.
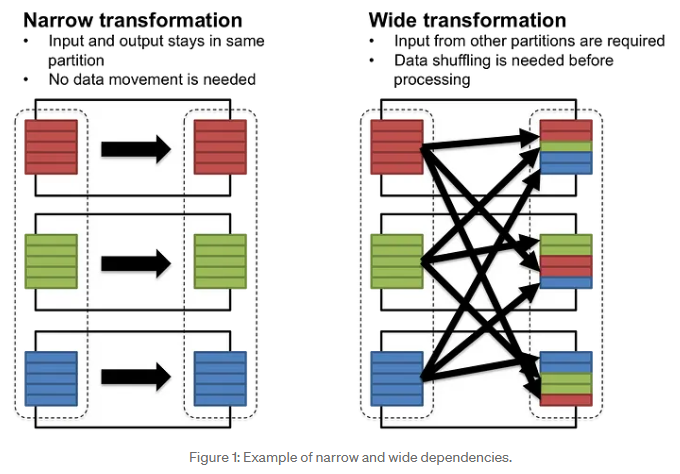
narrow transformation에서는 input과 output이 동일한 파티션에 머무는 것을 확인 할 수 있습니다.
반면 wide transformation은 데이터 셔플링이 요구되는 것을 볼 수 있습니다.
Narrow Transformation Function
| Narrow Transformation Function | Purpose | Example | Result |
|---|---|---|---|
map() | 각 요소에 함수를 적용하여 새 RDD 반환 | rdd.map(lambda x: x * 2) | 각 요소에 곱하기 2 |
filter() | 조건을 만족하는 요소만 포함하는 새 RDD 반환 | rdd.filter(lambda x: x > 2) | 2보다 큰 요소만 필터 인 |
flatMap() | map과 유사하지만 각 입력 요소를 0개 이상의 출력 요소로 매핑 | rdd.flatMap(lambda x: x.split(" ")) | 단어 단위로 나눠진 요소들 |
mapPartitions() | 각 파티션에 함수를 적용하고 새 RDD 반환 | rdd.mapPartitions(lambda x: [sum(x)]) | 각 파티션의 요소를 합산합니다. |
sample() | RDD의 샘플링된 하위 집합을 반환 | rdd.sample(False, 0.5, 42) | 요소의 무작위 50% 샘플 |
coalesce() | Reduces the number of partitions in the RDD | rdd.coalesce(1) | Single partition with all data |
Wide Transformation Function
| Wide Transformation Function | Purpose | Example | Result |
|---|---|---|---|
distinct() | 요소들의 고윳값으로 새 RDD 반환 | rdd.distinct() | 중복된 요소는 삭제됨 |
union() | 두 RDD의 합집합 반환 | rdd1.union(rdd2) | rdd1과 rdd2 요소가 합쳐짐 |
intersection() | 두 RDD의 교집합 | rdd1.intersection(rdd2) | rdd1과 rdd2 둘 모두에 있는 요소만 남음 |
subtract() | rdd2에는 없는 rdd1 요소만 반환 | rdd1.subtract(rdd2) | rdd1에는 있고 rdd2에는 없는 요소 |
cartesian() | 두 rdd의 all pair 반환 | rdd1.cartesian(rdd2) | 두 rdd에서 가능한 모든 pair |
groupBy() | 지정된 함수로 그룹화된 요소의 RDD를 반환 | rdd.groupBy(lambda x: x % 2) | 짝수/홀수 기준으로 요소를 그룹화 |
groupByKey() | ? | rdd.groupByKey() | 각 키의 값을 그룹화 |
reduceByKey() | 연관 함수를 사용하여 각 키의 값을 병합 | rdd.reduceByKey(lambda x, y: x + y) | 각 키의 값 합계 |
sortByKey() | 키를 기준으로 정렬된 RDD를 반환 | rdd.sortByKey() | 키별로 정렬된 RDD |
join() | 키로 두 개의 RDD를 join | rdd1.join(rdd2) | 일치하는 키가 있는 요소 쌍 |
repartition() | 데이터를 지정된 수의 파티션으로 다시 섞음 | rdd.repartition(4) | 데이터가 균등하게 분산된 4개의 파티션 |
Spark Transformation 사용 예
transformation 함수를 사용하기 전에 parallelize 함수부터 알아야합니다.
parallelize 함수는 리스트나 배열과 같은 로컬 컬렉션에서 RDD(Resilient Distributed Dataset)를 생성하는 데 사용됩니다.
이 기능은 데이터를 Spark 클러스터 전체에 분산시켜 병렬로 처리할 수 있도록 합니다.
rdd = sc.parallelize([1, 2, 3, 4, 5])파티션 수를 지정하여 RDD를 생성할 수도 있습니다.
(Spark의 최적화 및 배포 논리로 인해 정확히 3개의 파티션이 생성된다고 엄격하게 보장되지는 않습니다.)
rdd = sc.parallelize([1, 2, 3, 4, 5], numSlices=2)flatMap()
rdd = sparkContext.parallelize(["hello world", "apache spark"])
result = rdd.flatMap(lambda x: x.split(" ")).collect()
# result: ['hello', 'world', 'apache', 'spark']cartesian()
rdd1 = sparkContext.parallelize([1, 2])
rdd2 = sparkContext.parallelize(["a", "b"])
result = rdd1.cartesian(rdd2).collect()
# result: [(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')]mapPartitions()
두 번째 인자의 수 만큼 파티션을 나눈 다음에 각 파티션에 각 요소에 함수를 적용합니다.
rdd = sparkContext.parallelize([1, 2, 3, 4], 2)
result = rdd.mapPartitions(lambda x: [sum(x)]).collect()
# result: [3, 7]groupByKey()
리스트 안에 튜플에 key, value 형태로 구성된 데이터가 input으로 넣어보겠습니다.
groupByKey()를 사용하면 key에 해당하는 값(value가 아닌 key에 해당하는 값)을 기준으로 정렬이 되는 것을 알 수 있습니다.
rdd = sparkContext.parallelize([("a", 1), ("b", 2), ("a", 3)])
result = rdd.groupByKey().mapValues(list).collect()
# result: [('a', [1, 3]), ('b', [2])]reduceByKey()
key를 기준으로 하나의 value로 축소하는 연산을 진행합니다.
rdd = sparkContext.parallelize([("a", 1), ("b", 2), ("a", 3), ("a", 10)])
result = rdd.reduceByKey(lambda x, y: x + y).collect()
# result: [('a', 14), ('b', 2)]우선은 key를 기준으로 그룹화를 합니다. 이후 각 그룹에서 정의한 함수를 수행합니다.
x, y는 단순히 2개의 요소를 의미하는 게 아니라 2개 이상의 요소를 의미합니다.
value를 하나의 값으로 축소 될때까지 lambda 연산을 지속적으로 진행하는거죠.
“a” 키의 경우:
- 첫 번째 반복: x = 1, y = 3 -> 1 + 3 = 4
- 두 번째 반복: x = 4, y = 10 -> 4 + 10 = 14
- “a”의 최종 결과는 14입니다.
“b” 키의 경우:
- 하나의 값만 있으므로 축소가 필요하지 않습니다.
sortByKey()
rdd = sparkContext.parallelize([(2, "b"), (1, "a"), (3, "c")])
result = rdd.sortByKey().collect()
# result: [(1, 'a'), (2, 'b'), (3, 'c')]join()
rdd1 = sparkContext.parallelize([("a", 1), ("b", 2)])
rdd2 = sparkContext.parallelize([("a", 3), ("b", 4)])
result = rdd1.join(rdd2).collect()
# result: [('a', (1, 3)), ('b', (2, 4))]coalesce()
입력한 숫자만큼 파티션 수를 줄입니다.
rdd = sparkContext.parallelize([1, 2, 3, 4, 5, 6], 3)
result = rdd.coalesce(2).glom().collect()
# result: [[1, 2], [3, 4, 5, 6]]coalesce(2)
coalesce(2)는 RDD의 파티션 수를 2로 줄이는 변환입니다.
glom()
glom()은 RDD의 각 파티션 내의 모든 요소를 배열(또는 Python의 리스트)로 수집하여 배열의 RDD를 반환하는 작업입니다.
repartition()
지정된 수의 파티션으로 데이터를 섞습니다.
rdd = sparkContext.parallelize([1, 2, 3, 4, 5, 6], 2)
result = rdd.repartition(4).glom().collect()
# result: [[], [1, 2], [3, 4], [5, 6]] (result can vary due to shuffling)repartition(4)
지정된 수의 파티션(이 경우 4)에서 데이터를 다시 섞는 변환입니다.
참고하면 좋은 글
참고한 글

https://medium.com/@shagun/resilient-distributed-datasets-97c28c3a9411