Bifrost 아키텍쳐
학습 목표
- Bifrost 요청 흐름을
Transport → Routing/Load Balancing → Plugin Pipeline → Provider → Response관점으로 설명할 수 있습니다. - HTTP Gateway와 Go SDK 경로의 차이를 이해하고, Python 백엔드에서는 어떤 경로를 주로 사용하는지 판단할 수 있습니다.
- Plugin Pipeline의 PreHook/PostHook, short-circuit, streaming 처리 위치를 이해합니다.
- Provider API Communication 단계에서 인증, timeout, fallback, response parsing이 어디서 처리되는지 파악합니다.
- Self-hosted OSS 운영 시 관측성, 캐시, 거버넌스, MCP 도구 호출이 요청 흐름의 어느 지점에 들어가는지 설명할 수 있습니다.
핵심 개념
1. 전체 요청 흐름: Gateway는 단순 전달자가 아니라 요청 처리 파이프라인
Bifrost의 핵심 아키텍처는 “클라이언트 요청을 Provider API로 그대로 중계하는 프록시”가 아니라, 요청을 표준 내부 형식으로 바꾸고, 정책을 적용하고, Provider에 전달한 뒤, 응답을 다시 가공하는 파이프라인입니다.
공식 Request Flow 문서는 요청 처리를 다음 단계로 나누어 설명합니다.
| 단계 | 역할 | 운영 관점에서 보는 지점 |
|---|---|---|
| Transport Layer Processing | HTTP/SDK 요청 수신, header/body parsing, 내부 request schema 변환 | 인증 header, content-type, request body validation |
| Request Routing & Load Balancing | Provider/model/key 선택, fallback 판단 | 어떤 Provider와 key로 보냈는지, 왜 fallback 되었는지 |
| Plugin Pipeline Processing | PreHook 실행, request 변환, 인증/제한/캐시 정책 적용 | 요청 전처리, PII 마스킹, rate limit, semantic cache |
| MCP Tool Discovery & Integration | 요청에 필요한 tool discovery/filtering/injection | Agent별 tool 접근 제어, VK별 tool filtering |
| Memory Pool Management | request/response/channel 객체 재사용 | 고QPS 환경의 GC 부담, allocation 감소 |
| Worker Pool Processing | Provider 호출 작업을 worker에 배정 | 동시성, queue, timeout, saturation |
| Provider API Communication | Provider HTTP request 생성, 인증 추가, timeout 실행, 응답 parsing | Provider 장애, 인증 실패, latency, status code |
| Tool Execution & Response Processing | Provider가 반환한 tool call을 실행하고 결과를 반영 | MCP tool 실행, 승인 모드, tool 실패 대응 |
| Post-Processing & Response Formation | PostHook 실행, 응답 변환, 직렬화 | 로깅, 메트릭, 응답 후처리, streaming chunk 처리 |
이 흐름을 운영 관점으로 단순화하면 다음과 같습니다.
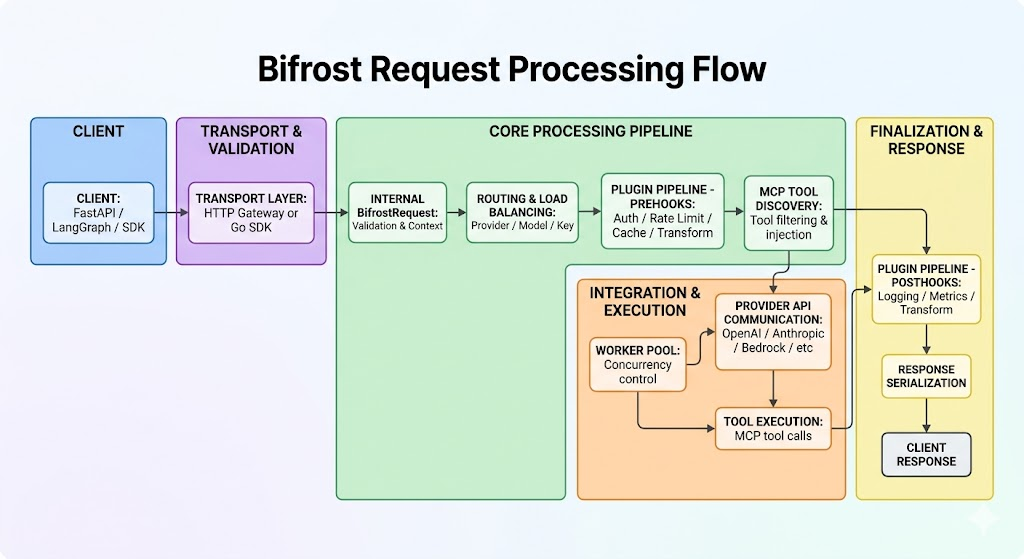
Python 백엔드 개발자는 대개 Client -> Trnasport layer만 직접 다룹니다.
즉 FastAPI/LangGraph 서비스는 Bifrost의 OpenAI-compatible endpoint를 호출하고, 그 뒤의 Provider 선택, key 선택, fallback, plugin, log, metrics는 Gateway 쪽 설정과 운영 정책으로 분리됩니다.
2. Transport Layer: 외부 요청을 Bifrost 내부 request로 바꾸는 입구
Transport Layer는 외부 클라이언트가 보낸 요청을 받아 Bifrost 내부에서 처리 가능한 표준 구조로 변환하는 계층입니다.
HTTP Gateway를 사용할 때는 FastHTTP 서버가 요청을 받고, header 처리, body parsing, JSON schema validation, 내부 BifrostRequest 변환, request context 생성을 수행합니다.
이 계층에서 중요한 점은 “Provider별 API 차이”를 애플리케이션 서비스가 직접 다루지 않게 만드는 것입니다.
예를 들어 FastAPI 서비스가 OpenAI-compatible 형태로 /v1/chat/completions를 호출하면, Bifrost는 이를 내부 request로 바꾼 뒤 이후 단계에서 Provider에 맞는 request로 다시 변환합니다.
| Transport 선택지 | 설명 | 적합한 경우 |
|---|---|---|
| HTTP Gateway | 외부 서비스가 HTTP/OpenAI-compatible API로 Bifrost 호출 | Python, Node.js, LangGraph, LangChain, 일반 백엔드 |
| Go SDK | Go 코드에서 Bifrost 내부 구조체 기반으로 직접 호출 | Go 서비스 내부 임베딩, HTTP/JSON overhead 최소화 필요 |
Python 백엔드/AI 개발자에게는 HTTP Gateway 방식이 기본입니다.
FastAPI, LangGraph, Celery worker, batch job 모두 같은 Gateway endpoint를 바라보게 만들 수 있기 때문입니다.
운영 체크포인트는 다음과 같습니다.
- 요청 header에 Virtual Key, tenant id, trace id, session id를 어떤 이름으로 실을지 정해야 합니다.
- request body validation 실패가 앱 버그인지, 클라이언트 입력 오류인지 구분해야 합니다.
- streaming 요청과 non-streaming 요청을 같은 endpoint에서 처리하더라도, downstream timeout과 client disconnect 처리를 별도로 봐야 합니다.
- API Gateway/Nginx/Ingress 앞단을 둔다면 body size limit, idle timeout, keep-alive 설정이 Bifrost timeout보다 먼저 끊기지 않도록 맞춰야 합니다.
3. Routing & Load Balancing: Provider, Model, Key를 결정하는 정책 계층
Transport Layer에서 내부 request가 만들어지면 Bifrost는 이 요청을 어느 Provider와 어느 API key로 보낼지 결정합니다.
이 단계가 중요한 이유는 AI Gateway의 운영 가치가 대부분 이곳에서 발생하기 때문입니다.
예를 들어 애플리케이션이 gpt-4o-mini 또는 openai/gpt-4o-mini 모델을 요청했다고 가정하겠습니다.
Bifrost는 모델 이름, Provider 설정, key pool, health check, fallback 정책, routing rule을 바탕으로 실제 호출 대상을 고릅니다.
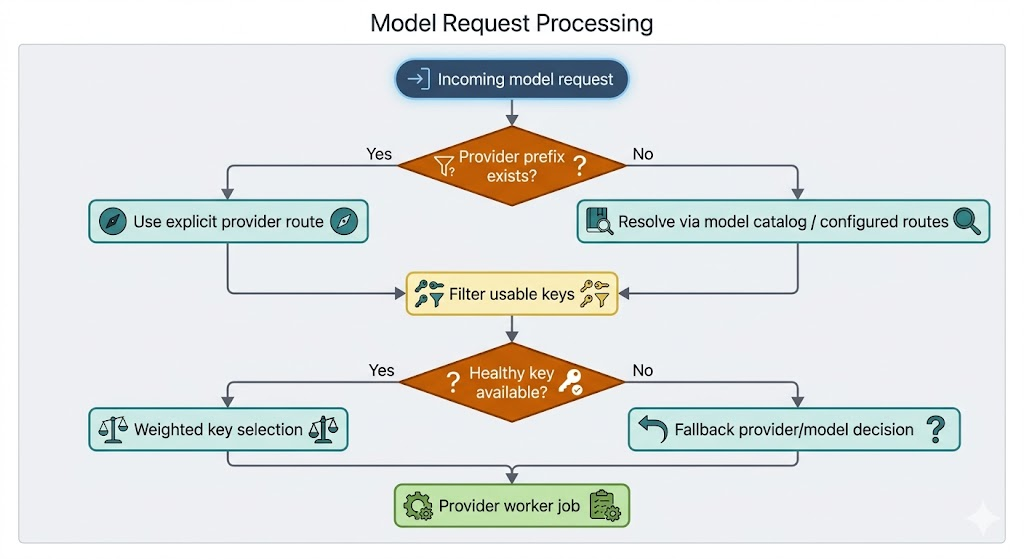
이 계층은 다음 절과 이후 Chapter에서 계속 확장됩니다.
| 기능 | 이 단계와의 관계 |
|---|---|
| Fallbacks | Provider/model/key 실패 시 다음 후보로 전환 |
| Load Balancing | 여러 key 또는 Provider에 가중치 기반 분산 |
| Keys Management | key pool, model-specific key, key failover 관리 |
| Routing Rules | Virtual Key, customer, team, model, request metadata에 따른 라우팅 |
| Budget & Rate Limits | 요청을 보내기 전에 사용량/한도를 검사하거나 제한 |
실무에서는 이 단계의 의사결정 로그가 매우 중요합니다.
“왜 OpenAI가 아니라 Anthropic으로 갔는가?”, “왜 이 key가 선택되었는가?”, “왜 fallback이 발생했는가?”를 추적할 수 있어야 장애와 비용 문제를 분석할 수 있습니다.
4. Plugin Pipeline: 요청 전후에 정책을 꽂는 확장 지점
Bifrost의 Plugin Pipeline은 핵심 요청 흐름을 수정하지 않고도 인증, rate limit, caching, logging, request transform, response transform 같은 기능을 추가할 수 있게 해주는 확장 계층입니다.
공식 Plugin 아키텍처는 plugin-first design, zero-copy integration, lifecycle management, interface-based safety, failure isolation을 핵심 원칙으로 설명합니다.
즉 plugin은 Gateway 핵심 로직을 바꾸지 않고도 동작하지만, plugin 오류가 전체 Gateway를 무너뜨리지 않도록 격리되어야 합니다.
Plugin Pipeline의 기본 실행 순서는 다음과 같습니다.
| 위치 | 실행 방향 | 대표 용도 |
|---|---|---|
| PreHooks | 등록 순서대로 실행 | 인증, rate limit, request validation, PII masking, semantic cache lookup, prompt policy |
| Provider Call | short-circuit이 없을 때 실행 | 실제 Provider API 호출 |
| PostHooks | PreHook의 역순으로 실행 | response logging, metrics, audit trail, response filtering, cost calculation |
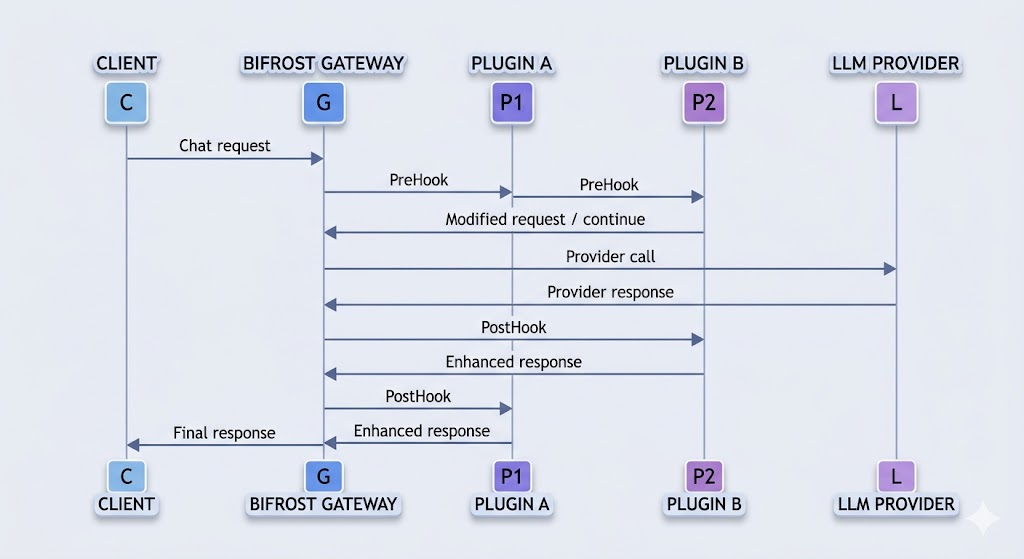
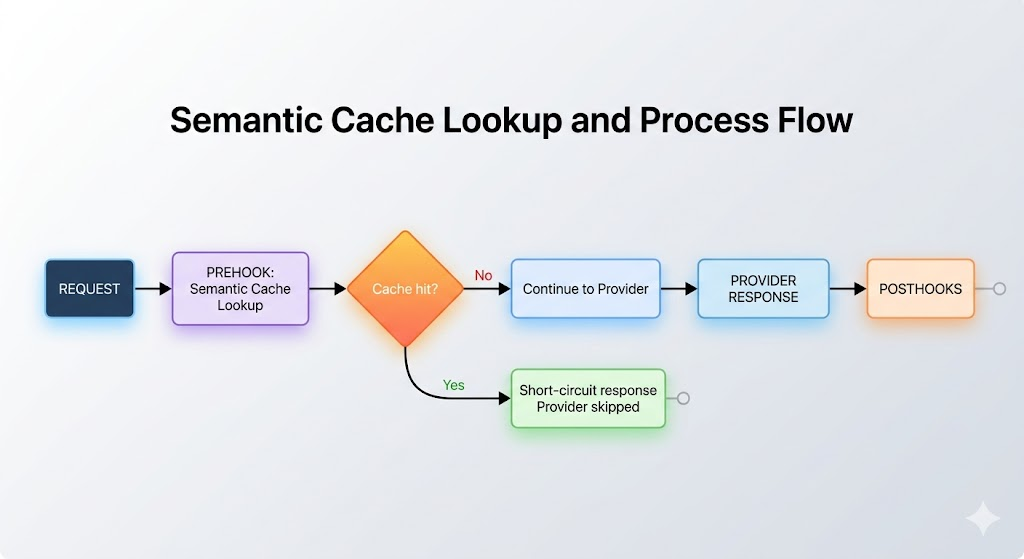
Plugin Pipeline에서 꼭 이해해야 할 개념은 short-circuit입니다.
어떤 plugin은 Provider 호출을 생략하고 바로 응답을 반환할 수 있습니다.
Semantic Cache가 대표적입니다. cache hit가 발생하면 Provider API를 호출하지 않고 cache response를 반환할 수 있습니다.
Streaming 요청에서는 PostHook이 최종 응답 한 번에만 실행되는 것이 아니라 provider가 반환하는 delta/chunk마다 실행될 수 있습니다.
따라서 streaming 환경의 plugin은 매우 가벼워야 하며, 무거운 로깅/분석 작업은 비동기화하거나 별도 queue로 넘기는 편이 안전합니다.
5. MCP Tool Discovery & Tool Execution: Agent 도구 호출은 요청 중간과 응답 이후에 모두 관여
Bifrost는 MCP Gateway 역할도 수행할 수 있습니다.
이때 MCP는 단순히 별도 기능이 아니라 LLM 요청 흐름 안에 들어옵니다.
요청 전 단계에서는 “이 요청에서 사용할 수 있는 tool 목록”을 찾아 request에 주입합니다.
이 과정에서 Virtual Key, customer, team, agent mode, include/exclude rule에 따라 tool을 필터링할 수 있습니다.
응답 이후에는 Provider가 tool call을 반환했을 때 실제 tool execution을 수행하고, 그 결과를 다시 응답 처리 흐름에 반영합니다.
| 시점 | MCP 관련 처리 | 예시 |
|---|---|---|
| Provider 호출 전 | Tool discovery, tool filtering, request enhancement | 특정 VK는 GitHub tool만 허용, 결제 tool은 차단 |
| Provider 응답 후 | Tool call 추출, tool execution, 결과 병합 | 모델이 search_docs tool call을 반환하면 MCP 서버에 실행 요청 |
| Agent Mode | 승인 없이 자동 실행 가능한 도구 정책 | 내부 read-only docs search는 자동 승인, write action은 제한 |
이 구조를 이해하면 Ch 8 MCP Gateway를 볼 때 훨씬 쉽습니다.
MCP는 “LLM이 tool을 쓴다”는 추상 개념이 아니라, Gateway 안에서 tool discovery, filtering, execution, response enhancement로 나뉘어 실행되는 운영 기능입니다.
6. Worker Pool과 Provider API Communication: 실제 Provider 호출 계층
Routing과 Plugin Pipeline을 지난 요청은 worker pool로 전달됩니다.
Worker Pool은 Provider 호출 작업을 worker에 배정하고, timeout과 동시성 제어 안에서 실제 Provider API 요청을 수행합니다.
Provider API Communication 단계에서는 다음 작업이 일어납니다.
- Bifrost response schema로 변환
- Provider별 HTTP request 생성
- Provider API key 또는 인증 정보 추가
- timeout context 설정
- HTTP client 실행
- 네트워크 오류, 4xx/5xx 오류, timeout 처리
- Provider response parsing
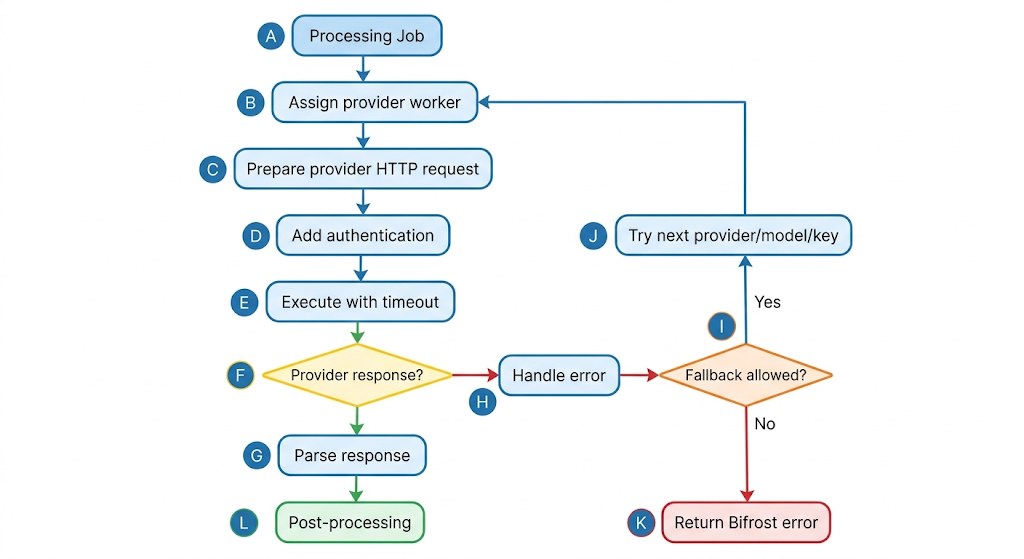
운영자는 이 단계에서 provider latency, timeout, retry/fallback 빈도, status code 분포를 봐야 합니다.
앱에서 “LLM이 느리다”고 느끼는 문제는 실제로는 Provider 지연, gateway queue saturation, upstream timeout, streaming chunk 지연, tool execution 지연 중 하나일 수 있습니다.
7. Framework Layer: ConfigStore, LogStore, VectorStore
Bifrost Framework는 plugin 생태계와 핵심 기능이 공통으로 사용하는 storage와 utility layer입니다.
공식 문서에서는 ConfigStore, LogStore, VectorStore, Pricing Module을 주요 구성요소로 설명합니다.
이 계층은 요청 흐름의 한 단계라기보다, 여러 기능이 공유하는 기반입니다.
| 구성요소 | 역할 | 연결되는 기능 |
|---|---|---|
| ConfigStore | Provider 설정, plugin 설정, system state 저장 | Provider 등록, key 설정, UI 기반 설정, 동적 업데이트 |
| LogStore | structured logging, audit trail, search/filter, pagination | Observability, Logging API, request debugging |
| VectorStore | embedding, similarity search, namespace isolation | Semantic Caching, AI-powered search |
| Pricing Module | model pricing, usage tracking, cost calculation | Budget, rate limit, customer billing, pricing override |
Self-hosted OSS에서 이 계층은 특히 중요합니다.
Docker로 빠르게 띄운 뒤에도 운영으로 넘어가려면 설정과 로그가 사라지지 않아야 하고, semantic cache를 쓴다면 vector store의 namespace, retention, backup 전략도 필요합니다.
8. Python 백엔드 관점의 아키텍처 경계
FastAPI/LangGraph 개발자는 Bifrost 내부의 모든 단계를 직접 구현하지 않습니다.
대신 경계를 정확히 나누는 것이 중요합니다.
| 계층 | Python 애플리케이션 책임 | Bifrost 책임 |
|---|---|---|
| Request 생성 | user message, system prompt, tool schema, session id 구성 | request validation, 내부 schema 변환 |
| 모델 선택 | 비즈니스 요구에 맞는 논리 모델명 선택 | Provider/model/key routing, fallback |
| 인증 | 사용자 인증, 서비스 인증, tenant 식별 | Provider key 보관, Virtual Key 정책 |
| 비용 | 기능별 비용 목표 정의 | token/cost logging, budget/rate limit 적용 |
| 장애 대응 | 사용자 경험, graceful fallback message | provider failover, retry/fallback, error normalization |
| 관측성 | application trace/span 생성 | LLM request log, provider latency, token/cost metrics |
| Tool 사용 | LangGraph node/tool 설계 | MCP tool discovery/filtering/execution gateway |
좋은 설계는 LLM 호출을 애플리케이션 곳곳에 흩뿌리지 않고, llm_client.py, model_gateway.py, agent_runtime.py 같은 한두 개의 경계로 모으는 것입니다.
그래야 Bifrost base URL, Virtual Key, trace header, timeout, model naming convention을 중앙에서 관리할 수 있습니다.
⚠️ 주의점
⚠️ Plugin Pipeline은 매우 강력하지만, 모든 정책을 plugin에 밀어 넣으면 요청 latency와 장애 표면이 커집니다. 특히 streaming 응답의 post-hook은 chunk마다 실행될 수 있으므로 heavy processing, 외부 API 호출, 동기 DB write를 직접 넣지 않는 것이 좋습니다.
⚠️ Provider fallback은 장애 대응 수단이지 품질 보존을 자동 보장하는 기능이 아닙니다. OpenAI에서 Anthropic, Bedrock, Gemini 등으로 fallback할 때 tool schema, system prompt 해석, safety policy, token limit, response format 차이가 생길 수 있으므로 회귀 테스트가 필요합니다.
⚠️ Gateway를 도입하면 애플리케이션 로그만으로는 LLM 문제를 충분히 분석하기 어렵습니다. request_id, customer_id, model, provider, key, fallback 여부, cache hit 여부, latency, token, cost를 Gateway 로그와 함께 연결해야 합니다.
