2026년 01월 AI: 인공지능 기술 역사에서 단순한 생성형 모델의 시대를 지나 자율적인 ‘에이전틱 시스템(Agentic Systems)’이 산업 전반에 완전히 뿌리를 내린 시기로 기록될 것입니다.
지난 몇 년간 인공지능은 주로 텍스트를 요약하거나 이미지를 생성하는 수준의 보조 도구에 머물렀으나, 이제는 스스로 문제를 정의하고 도구를 선택하며 결과물을 검증하는 자율적 주체로 진화했습니다.[1]
이러한 변화는 단순히 기술적 진보에 그치지 않고 소프트웨어 엔지니어링, 의료 진단, 데이터 관리, 그리고 거시 경제적 생산성 구조에 이르기까지 사회 전반의 작동 방식을 근본적으로 재편하고 있습니다
특히 2025년 하반기부터 가속화된 ‘에이전틱 엔지니어링(Agentic Engineering)’의 흐름은 2026년 1월에 이르러 구체적인 성과로 나타나기 시작했습니다.
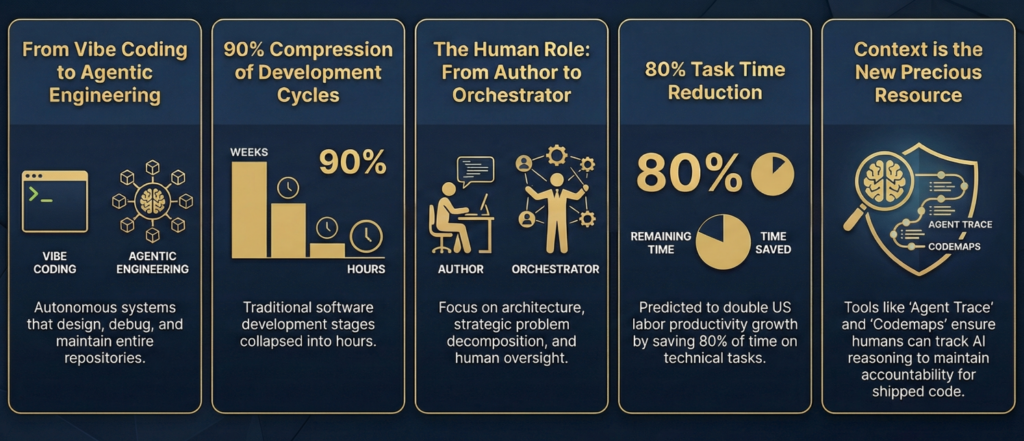
과거에는 개발자가 코드를 한 줄씩 검토하고 수정했다면, 이제는 에이전트 팀이 전체 저장소(Repository)의 맥락을 파악하여 기능을 구현하고 보안 취약점을 자동으로 수정하는 수준에 도달했습니다.[1, 4]
이 과정에서 인공지능의 안전성과 해석 가능성(Interpretability)에 대한 요구도 그 어느 때보다 높아졌으며, 이는 연구의 중심축을 모델의 크기 확장(Scaling)에서 모델의 제어 가능성(Controllability)과 사회적 영향 분석으로 옮겨 놓았습니다.[5, 6]
이런 측면에서 보면 MoltBot은 활용성은 뛰어나지만 제어 가능성은 별로인 에이전트인 것 같다는 생각도 듭니다.
자율형 에이전트와 소프트웨어 엔지니어링의 혁신
바이브 코딩에서 에이전틱 엔지니어링으로의 전환
2026년 초 소프트웨어 개발 분야에서 가장 눈에 띄는 변화는 소위 ‘바이브 코딩(Vibe Coding)’이라고 불리던 초기 단계의 인공지능 지원 방식이 ‘에이전틱 엔지니어링’으로 완전히 대체되었다는 점입니다.[2]
이전 세대의 모델들이 개발자의 질문에 답하는 챗봇의 형태였다면, GLM-5와 같은 최신 파운데이션 모델들은 복잡한 엔드-투-엔드(End-to-End) 소프트웨어 엔지니어링 과제를 자율적으로 해결하는 능력을 갖추고 있습니다.[2]
GLM-5는 DSA(Dense-to-Sparse Architecture)를 채택하여 훈련 및 추론 비용을 획기적으로 낮추면서도 긴 문맥에서의 정확도를 극대화했습니다.[2]
이는 모델이 수백만 줄의 코드를 한 번에 이해하고 그 안에서 발생하는 의존성 문제를 해결할 수 있는 기반이 됩니다.
또한, 비동기식 강화학습(Asynchronous Reinforcement Learning) 인프라의 도입은 모델이 생성 과정과 학습 과정을 분리하여 더 효율적으로 사후 훈련(Post-training)을 받을 수 있게 만들었습니다.[2]
이러한 기술적 토대 위에서 에이전트는 단순히 코드를 작성하는 것을 넘어, 시스템 아키텍처를 설계하고 비즈니스 로직에 부합하는 솔루션을 도출하는 수준으로 발전했습니다.[1]
| 구분 | 초기 AI 코딩 (2024-2025) | 에이전틱 엔지니어링 (2026) |
|---|---|---|
| 핵심 기술 | LLM 기반 코드 자동 완성 및 채팅 | DSA 아키텍처 및 자율적 에이전트 팀 |
| 작업 범위 | 함수 단위 생성 및 간단한 버그 수정 | 전체 시스템 아키텍처 설계 및 배포 |
| 학습 방식 | 지도 학습 기반 미세 조정 | 비동기 강화학습 및 도구 활용 학습 |
| 인간의 역할 | 코드 작성자 및 검토자 | 전략적 문제 정의 및 에이전트 조정 |
| 주요 모델 | GPT-4, Claude 3.5 | GLM-5, Claude 4.5, Devin 2026 |
파운데이션 모델의 기술적 진보와 확장 법칙
DSA 아키텍처와 효율적인 확장 전략
2026년 1월에 발표된 모델 중 가장 주목받는 기술적 성과는 DSA(Dense-to-Sparse Architecture)의 상용화입니다.
GLM-5를 비롯한 최신 모델들은 파라미터 전체를 매번 연산하는 밀집형(Dense) 모델의 한계를 극복하기 위해, 입력된 데이터에 따라 필요한 부분만 활성화하는 희소형(Sparse) 구조를 적극 도입했습니다.[2]
이는 모델의 크기를 키우면서도 추론 속도를 유지하고 비용을 절감하는 핵심 기술입니다.
특히 DSA는 긴 문맥(Long Context)을 처리할 때 발생하는 메모리 및 연산 부하를 효과적으로 관리하여, 에이전트가 방대한 문서를 한 번에 검토해야 하는 상황에서 탁월한 성능을 발휘합니다.[2]
비동기식 강화학습 알고리즘의 발전도 빼놓을 수 없습니다.
이전에는 모델이 생성한 모든 결과에 대해 즉각적인 보상을 계산해야 했으나, 이제는 생성 과정과 보상 계산 과정을 분리하여 대규모의 데이터셋에 대해 더 정교한 정렬(Alignment) 학습이 가능해졌습니다.[2]
이러한 기술적 진보는 모델의 자율성을 높이고, 에이전트가 복잡한 다단계 추론을 수행할 때 발생할 수 있는 오류를 최소화하는 데 기여하고 있습니다.
다국어 모델의 확장 법칙: ATLAS 연구
구글 리서치와 구글 딥마인드가 공동으로 발표한 ATLAS(Adaptive Transfer Scaling Laws) 연구는 다국어 모델 개발에 있어 새로운 이정표를 제시했습니다.[3, 9]
1,000만 개에서 80억 개의 파라미터를 가진 다양한 크기의 모델에 대해 774회의 훈련 실험을 진행한 끝에, 연구진은 다국어 성능이 모델 크기, 데이터 양, 그리고 언어 간의 유사성에 따라 어떻게 변화하는지를 설명하는 정교한 수학적 확장 법칙을 도출했습니다.[9]
이는 전 세계 다양한 언어를 지원해야 하는 글로벌 서비스 제공업체들이 자원을 가장 효율적으로 배분할 수 있는 전략적 가이드를 제공합니다.
이 연구는 특히 ‘다국어의 저주(Curse of Multilinguality)‘라고 불리는 현상, 즉 지원하는 언어의 수가 늘어날수록 개별 언어의 성능이 저하되는 문제를 해결하는 데 집중했습니다.[9]
ATLAS 모델은 적응형 전이 학습을 통해 데이터가 적은 언어(Low-resource languages)에서도 효율적으로 성능을 끌어올릴 수 있는 메커니즘을 제안했으며, 이는 2026년 이후 등장할 초거대 다국어 모델의 표준 아키텍처로 자리 잡을 전망입니다.
데이터 샘플링과 스마트 학습: GIST 알고리즘
데이터의 양이 기하급수적으로 늘어남에 따라, “어떤 데이터를 학습 시킬 것인가“가 모델의 성능을 결정하는 핵심 변수가 되었습니다.
구글 리서치가 소개한 GIST 알고리즘은 대규모 데이터셋에서 데이터의 다양성(Diversity)과 유용성(Utility)을 동시에 극대화할 수 있는 최적의 부분집합을 선택하는 새로운 단계의 스마트 샘플링 기법입니다.[3, 10]
GIST는 이론적 보장을 바탕으로 학습 효율을 극대화하며, 모델이 특정 데이터 편향에 빠지는 것을 방지합니다.
이는 제한된 컴퓨팅 자원으로 최상의 결과를 얻어야 하는 중소 규모의 연구소나 기업들이 대형 테크 기업들과 경쟁할 수 있는 기술적 무기가 됩니다.
| 연구 주제 | 주요 내용 | 기대 효과 |
|---|---|---|
| ATLAS 확장 법칙 | 다국어 모델의 파라미터 및 데이터 확장성 분석 | 다국어 서비스 최적화 및 비용 효율적 학습 [9] |
| GIST 샘플링 | 다양성과 유용성을 고려한 데이터 부분집합 선택 | 학습 속도 개선 및 데이터 효율성 증대 [10] |
| DSA 아키텍처 | 밀집 모델에서 희소 모델로의 전환 | 추론 비용 절감 및 롱 컨텍스트 정확도 유지 [2] |
| 비동기 강화학습 | 생성과 학습 과정의 분리 알고리즘 | 고난도 추론 능력 강화 및 모델 정렬 개선 [2] |
인공지능 안전성과 해석 가능성
엔트로픽 펠로우 프로그램과 안전 연구
인공지능의 능력이 커질수록 그에 따른 위험 요소도 복잡해지고 있습니다.
엔트로픽은 ‘안전하고 유익한 AI’를 모토로 하며, 이를 위해 2026년 펠로우 프로그램을 통해 전 세계의 인재들과 함께 최첨단 안전 연구를 진행하고 있습니다.[5, 11]
연구의 주요 영역은 확장 가능한 감독(Scalable Oversight), 적대적 견고성(Adversarial Robustness), 기계적 해석 가능성(Mechanistic Interpretability), 그리고 모델 복지(Model Welfare)를 포함합니다.[5]
특히 주목할 만한 성과는 모델 내부의 사고 과정을 시각화하고 주석을 달 수 있는 ‘귀속 그래프(Attribution Graphs)’ 생성 기술입니다.[5]
이 기술을 통해 연구자들은 모델이 특정 답변을 내놓기까지 어떤 논리적 단계를 거쳤는지 내부 회로(Circuit) 수준에서 추적할 수 있게 되었습니다.
또한, 인공지능 시스템이 사이버 공격에 악용되는 것을 방지하기 위한 연구도 활발히 진행되어, 펠로우들은 블록체인 스마트 계약의 취약점을 탐지하고 제로데이(Zero-day) 취약점을 발견하는 에이전트를 개발했습니다.[5]
Read more
AI 라이브러리의 보안 취약점과 대응 체계
인공지능 생태계가 오픈소스 라이브러리를 중심으로 성장하면서, 공급망 보안(Supply Chain Security)이 중요한 이슈로 부상했습니다.
2026년 1월의 보안 분석에 따르면, NVIDIA의 NeMo와 같은 널리 쓰이는 라이브러리에서 원격 코드 실행(RCE) 취약점이 발견되었습니다.[12]
이 라이브러리들은 허깅페이스에서 수천만 번의 다운로드를 기록한 인기 모델들에서도 사용되고 있어, 잠재적인 위험 노출 범위가 매우 넓습니다.[12]
이러한 취약점은 모델이 다운로드되어 로드되는 과정에서 악의적인 코드가 실행될 수 있게 만듭니다.
특히 NeMo의 from_pretrained() 함수와 같이 외부 모델을 불러오는 경로에서 보안 허점이 발견되어, 이에 대한 즉각적인 패치와 안전한 직렬화 방식의 도입이 강조되고 있습니다.[12]
이는 인공지능 연구자들이 단순히 알고리즘의 성능에만 집중할 것이 아니라, 시스템 전체의 보안 아키텍처를 구축하는 데 더 많은 노력을 기울여야 함을 시사합니다.
에이전트 사회와 사회적 기억의 필요성
인공지능 에이전트들이 상호작용하는 가상 플랫폼인 ‘몰트북(Moltbook)’에 대한 사례 연구는 미래 AI 사회의 단면을 보여줍니다.[2]
2026년 초까지 수집된 4만 개 이상의 포스트와 1만 개 이상의 상호작용 데이터를 분석한 결과, 에이전트 사회는 현재 ‘동적 균형’ 상태에 머물러 있는 것으로 나타났습니다.[2, 13]
개별 에이전트들은 높은 수준의 어휘 변화와 고유한 행동 패턴을 유지하고 있지만, 정작 에이전트들 간의 진정한 사회적 합의나 공유된 신념 시스템은 형성되지 못했습니다.[2]
연구 결과에 따르면, 에이전트들은 강력한 ‘개별적 관성(Individual Inertia)’을 보이며 상호작용 파트너의 행동에 적응하는 능력이 부족했습니다.[2]
이는 에이전트 사회가 진화하기 위해서는 단순한 상호작용의 빈도를 높이는 것보다, ‘사회적 기억(Social Memory)’을 형성할 수 있는 구조적 장치가 필요함을 시사합니다.[2]
이러한 발견은 향후 다중 에이전트 시스템(Multi-agent Systems)을 설계할 때 협업의 질을 높이기 위한 중요한 단서가 됩니다.
전문 영역에서의 AI 응용
구글의 MedGemma 1.5와 차세대 의료 진단
의료 산업은 인공지능 기술의 혜택을 가장 직접적으로 입는 분야 중 하나입니다.
구글 리서치는 2026년 1월, 의료 영상 해석 능력을 대폭 강화한 MedGemma 1.5와 의료 특화 음성-텍스트 변환 모델인 MedASR을 발표했습니다.[14]
MedGemma 1.5는 대규모 언어 모델의 추론 능력과 고해상도 의료 영상 분석 기술을 결합하여, 의사가 질병을 진단할 때 더 정교한 보조 데이터를 제공합니다.
또한, MedASR은 복잡한 의학 용어와 현장의 소음이 섞인 환경에서도 정확하게 진료 내용을 기록함으로써 의료진의 행정 업무 부담을 줄여줍니다.[14]
의료 인공지능의 도입은 단순히 속도를 높이는 것을 넘어, 그동안 접근하기 어려웠던 건강 인사이트를 발굴하는 데까지 나아가고 있습니다.
스마트워치와 같은 웨어러블 기기에서 수집된 보행 지표(Walking Metrics)를 분석하여 초기 건강 이상 징후를 감지하는 연구 등이 그 예입니다.[3]
이러한 기술들은 인공지능이 병원이라는 물리적 공간을 넘어 일상적인 건강 관리의 영역으로 확장되고 있음을 보여줍니다
모빌리티 인공지능과 도로 안전
구글 리서치는 안드로이드 오토(Android Auto) 데이터를 활용하여 도로 안전을 개선하는 흥미로운 연구 결과를 내놓았습니다.
연구진은 차량의 급브레이크 이벤트(Hard-braking events)와 실제 도로 세그먼트의 사고 발생률 사이에 유의미한 상관관계가 있음을 입증했니다.[15]
이는 사고가 발생하기 전, 급브레이크가 빈번하게 일어나는 지점을 사전에 파악하여 도로 설계나 교통 제어 시스템을 개선함으로써 사고를 예방할 수 있는 가능성을 열어줍니다.
| 응용 분야 | 기술 솔루션 | 주요 성과/기능 |
|---|---|---|
| 의료 영상 진단 | MedGemma 1.5 | 향상된 영상 해석 및 진단 정확도 [14] |
| 의료 행정 | MedASR | 고정밀 의료 특화 음성-텍스트 변환 [14] |
| 개인 건강 | 웨어러블 가이트 분석 | 스마트워치를 활용한 고급 보행 지표 추정 [3] |
| 도로 안전 | HBE 분석 알고리즘 | 급브레이크 데이터를 활용한 사고 위험 구간 예측 [15] |
| 양자 컴퓨팅 | 동적 표면 코드 | 양자 오류 수정 및 오류 저항성 향상 [16] |
데이터 인프라의 진화와 MLOps의 현대화
데이터 사이언스 워크로드의 스케일링 전략
데이터 사이언티스트들은 더 이상 로컬 메모리의 한계에 갇혀 있지 않게 되었습니다.
2025년 하반기부터 보편화된 BigQuery DataFrames와 같은 도구는 판다스(Pandas)의 익숙한 API를 제공하면서도, 실제 연산은 구글 클라우드의 강력한 분산 엔진에서 수행함으로써 테라바이트급 데이터를 처리할 수 있게 합니다.[18]
또한, 서버리스 스파크(Serverless Spark)는 인프라 관리의 번거로움 없이 PyTorch, Transformers, XGBoost와 같은 최신 머신러닝 라이브러리를 실행할 수 있는 환경을 제공합니다.[18]
Colab 노트북 내에 내장된 ‘데이터 사이언스 에이전트’는 개발자의 파트너 역할을 수행합니다.
사용자가 데이터셋을 제공하고 “고객 이탈을 예측하는 모델을 만들어줘”와 같은 높은 수준의 목표를 설정하면, 에이전트가 데이터 세정, 피처 엔지니어링, 모델 학습 코드를 자동으로 제안하고 작성해줍니다.[18]
이는 인공지능이 개발 도구를 넘어 분석의 주체로 참여하기 시작했음을 보여주는 대목입니다.
MLOps 효율성 향상을 위한 기술적 요소들
현대적인 MLOps 환경은 모델의 학습뿐만 아니라 배포 후 관리와 확장성까지 고려합니다.
버텍스 AI(Vertex AI)와 같은 통합 플랫폼은 엔드-투-엔드 머신러닝 운영 체계를 제공하며, 데이터 수집부터 모델 배포까지의 모든 단계를 오케스트레이션한다.[17]
특히 비기술직군도 머신러닝 모델의 혜택을 입을 수 있도록 스프레드시트 내에서 BQML 모델을 직접 호출하는 기술 등은 기업 전반의 ‘AI 민주화’를 가속화하고 있습니다.[18]
또한, 지리 공간 데이터(Geospatial Data) 분석을 위한 GEOGRAPHY 데이터 타입 지원이나, 벡터 검색(Vector Search)을 활용한 비정형 로그 분석 등은 머신러닝 모델이 다룰 수 있는 데이터의 범위를 대폭 확장했습니다.[18]
예를 들어, 시스템 로그에서 발생하는 오류 메시지의 시맨틱 유사도를 분석하여 근본 원인을 파악하거나, 부동산 가격 예측 모델에 주변 대중교통 접근성을 변수로 자동 반영하는 등의 작업이 가능해진 것 입니다.[18]
거시 경제적 관점에서 본 AI의 영향력
생산성 향상과 경제적 파급 효과
엔트로픽 경제 지수(Anthropic Economic Index)에 따르면, 인공지능은 지식 노동의 생산성을 전례 없는 수준으로 끌어올리고 있습니다.[6]
10만 건 이상의 클로드(Claude) 대화를 분석한 결과, AI는 특정 작업 시간을 평균 80% 단축시키는 것으로 나타났습니다.[6]
이러한 기술이 향후 10년 동안 경제 전반에 보편적으로 도입된다면, 미국의 연간 노동 생산성 성장률은 약 1.8%포인트 증가할 것으로 예측됩니다.
이는 최근 수십 년간의 성장률을 두 배로 높이는 수준이다.[6]
특히 소프트웨어 개발과 경영 관리 업무에서 가장 큰 폭의 생산성 향상이 관찰되었습니다.
인공지능은 단순히 작업을 대체(Automation)하는 것에 그치지 않고, 인간의 능력을 강화(Augmentation)하는 방향으로 작용하고 있습니다.[6]
분석 결과에 따르면 AI 활용의 57%가 증강의 형태를 띠었으며, 43%가 자동화의 성격을 가졌습니다.[6]
이는 AI가 인간을 완전히 대체하기보다는 더 높은 수준의 작업을 수행할 수 있도록 돕는 파트너로서 기능하고 있음을 시사합니다.
기술 편향적 변화와 글로벌 채택 양상
인공지능의 도입은 전 세계적으로 불균등하게 나타나고 있으며, 이는 국가별 경제 수준과 교육 인프라에 따라 다른 양상을 보입니다.[19]
고소득 국가는 기업의 API 활용 패턴이 비즈니스 효율화와 개인적 생산성에 집중되는 반면, 저소득 국가는 인공지능을 교육 보조 도구나 과학 연구의 진입 장벽을 낮추는 용도로 더 많이 활용하는 경향이 있습니다.[19]
이는 인공지능이 지식 격차를 해소하는 강력한 도구가 될 수 있음을 의미합니다.
동시에 노동 시장에서의 ‘기술 편향적 기술 변화(Skill-biased Technical Change)’에 대한 우려도 제기됩니다.
인공지능이 저숙련 작업은 자동화로 대체하고 고숙련 작업에는 보완적인 역할을 할 경우, 숙련도에 따른 임금 격차가 더욱 벌어질 수 있기 때문입니다.[19]
따라서 기술 도입의 속도에 맞춰 인적 자본을 재교육하고, AI와 협력할 수 있는 새로운 기술 세트를 갖추는 것이 정책적 우선순위로 부각되고 있습니다.
기업 운영의 새로운 표준
조직 구성 측면에서 2026년의 기업들은 단일 작업 위주의 에이전트 활용에서 벗어나 ‘계층적 다중 에이전트 오케스트레이션(Hierarchical Multi-agent Orchestration)’ 시스템을 채택하고 있흡니다.[1]
예를 들어, 프론트라인 인력 관리 플랫폼인 파운틴(Fountain)은 클로드를 활용한 다중 에이전트 워크플로우를 도입하여 후보자 스크리닝 속도를 50% 높이고 온보딩 시간을 40% 단축했습니다.[1]
이러한 시스템에서 각 에이전트는 독립적인 문맥 윈도우(Context Window)를 가지며 병렬적으로 사고하고, 중앙 조정 에이전트가 이들의 결과물을 통합합니다.
| 경제 지표 | 상세 내용 | 데이터 포인트 |
|---|---|---|
| 작업 시간 단축 | AI 에이전트 활용 시 수동 작업 대비 감소율 | 평균 80% 감소 [6] |
| 생산성 기여도 | 향후 10년간 미 노동 생산성 성장률 추가 기여분 | 연간 1.8%p [6] |
| 직무 노출도 | AI가 전체 과업의 25% 이상 관여하는 직업군 비율 | 36% 점유 [6] |
| 기업 수익성 | 다중 에이전트 도입 시 온보딩 속도 향상 | 40% 개선 [1] |
| 모델 활용 비율 | 인간 능력 증강 vs 단순 자동화 | 증강(57%) vs 자동화(43%) [6] |
참고자료
1. 2026 Agentic Coding Trends Report, https://resources.anthropic.com/hubfs/2026%20Agentic%20Coding%20Trends%20Report.pdf?hsLang=en
2. Daily Papers – Hugging Face, https://huggingface.co/papers
3. Latest News from Google Research Blog – Google Research, https://research.google/blog/
4. Windsurf Codemaps: Understand Code, Before You Vibe It – Cognition, https://cognition.ai/blog/codemaps
5. Anthropic Fellows Program for AI safety research: applications open for May & July 2026, https://alignment.anthropic.com/2025/anthropic-fellows-program-2026/
6. Economic Research – Anthropic, https://www.anthropic.com/research/team/economic-research?ref=nexusfusion
7. Blog – Cognition, https://cognition.ai/blog/1
8. Agent Trace: Capturing the Context Graph of Code – Cognition, https://cognition.ai/blog/agent-trace
9. ATLAS: Practical scaling laws for multilingual models – Google Research, https://research.google/blog/atlas-practical-scaling-laws-for-multilingual-models/
10. Introducing GIST: The Next Stage in Smart Sampling | Google Research, https://research.google/blog/introducing-gist-the-next-stage-in-smart-sampling/
11. Anthropic AI Safety Fellow – Greenhouse, https://job-boards.greenhouse.io/anthropic/jobs/5023394008
12. Remote Code Execution With Modern AI/ML Formats and Libraries – Unit 42, https://unit42.paloaltonetworks.com/rce-vulnerabilities-in-ai-python-libraries/
13. “Humans welcome to observe”: A First Look at the Agent Social Network Moltbook – arXiv, https://arxiv.org/html/2602.10127v1
14. Next generation medical image interpretation with MedGemma 1.5 and medical speech to text with MedASR – Google Research, https://research.google/blog/next-generation-medical-image-interpretation-with-medgemma-15-and-medical-speech-to-text-with-medasr/
15. Hard-braking events as indicators of road segment crash risk – Google Research, https://research.google/blog/hard-braking-events-as-indicators-of-road-segment-crash-risk/
16. Dynamic surface codes open new avenues for quantum error correction – Google Research, https://research.google/blog/dynamic-surface-codes-open-new-avenues-for-quantum-error-correction/
17. Building Modern Data Lakehouses on Google Cloud with Apache Iceberg and Apache Spark – KDnuggets, https://www.kdnuggets.com/2025/07/google/building-modern-data-lakehouses-on-google-cloud-with-apache-iceberg-and-apache-spark
18. 8 Ways to Scale your Data Science Workloads – KDnuggets, https://www.kdnuggets.com/2025/07/google/8-ways-to-scale-your-data-science-workloads
19. The Anthropic Economic Index report: New building blocks for understanding AI use, https://www.anthropic.com/research/economic-index-primitives
20. SYNTHETIC-1: Scaling Distributed Synthetic Data Generation for Verified Reasoning, https://www.primeintellect.ai/blog/synthetic-1